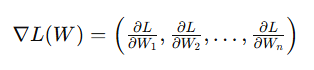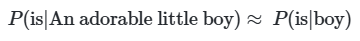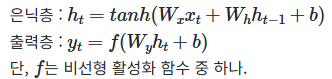대표적인 이미지 생성 모델들 - GAN, VAE, Flow-base model, Diffusion
모두 생성 모델링을 위한 딥러닝 아키텍처에 속함
생성 모델: 입력 이미지에 대한 분포 p(x)를 학습해 새로운 이미지(새로운 이미지이면서 기존 이미지에서 특성을 추출했기에 최대한 입력이미지와 유사한 이미지)를 생성하는 것을 목표로 함
1. GAN (Generative Adversarial Networks)
상호 적대적인 생성자(generator, G)와 판별자(Discriminator, D)라는 두 개의 신경망을 이용한 적대적 생성 모델
생성자는 주어진 데이터 분포와 유사한 새로운 데이터를 생성하고, 판별자는 생성된 데이터와 실제 데이터를 구별함
생성자와 구별자는 경쟁을 통해 성능을 개선시키고, 생성자는 실제 데이터와 구별할 수 없는 데이터를 생성하게 됨
장점 : 1. 다양한 데이터 학습이 가능 2. 기존의 생성 모델보다 정교한 데이터 생성 가능
단점 : 1. 많은 양의 데이터가 요구됨 2. 안정적인 학습이 어려울 수 있음
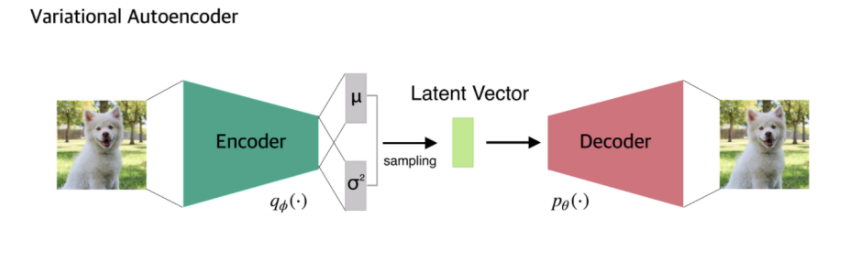
2. VAE (Variational Autoencoder)
input data를 가장 잘 표현하는 feature를 추출해 latent vector z를 통해 X와 유사하지만 새로운 데이터를 생성해내는데 목표를 가짐
이미지의 latent space에서 sampling해 완전히 새로운 이미지나 기존 이미지를 변형하는 방식을 사용함
이때 사용되는 확률분포 z는 latent vector라고 불림
encoder: x를 입력받아 z와 대응되는 평균과 분산을 구하는 네트워크 = q(z|x)
decoder: z를 입력받아 x와 대응되는 평균과 분산을 구하는 네트워크 = p(x|z)
Autoencoder(AE)와 확률적 요소를 결합한 모델
Autoencoder: 데이터의 압축(or 차원 축소) 및 잠재 변수(latent variable) 표현을 학습하는 데 사용되는 신경망 아키텍처
결정론적 모델로 입력 데이터를 고정된 잠재 변수 표현으로 매핑하고 디코딩함(VAE는 확률 분포를 사용해 잠재 변수 모델링함)
VAE는 데이터 생성과 잠재 변수 공간에서의 탐색에 적합한 모델인 반면, Autoencoder는 주로 데이터 압축 및 잠재 변수 표현에 중점을 둔 모델
오토인코더처럼 Unsupervised Learning이기 때문에 입출력이 같기를 원하는 상황은 똑같지만, VAE는 latent vector가 평균 분산으로 이루어진 가우시안 분포를 가지게 되고, AE는 잠재 코드가 어떠한 행렬로 나오게 됨
훈련 목적 함수로 ELBO(Evidence Lower Bound)를 사용하며, 이를 최대화하는 방식으로 훈련됨
ELBO: 잠재 변수 Z에 대한 관측 데이터 X의 로그 우도와 잠재 변수의 확률 분포와 사전 확률 분포 간의 Kullback-Leibler(KL) 발산의 합으로 구성됨
인코더는 가우시안 분포를 따르는 것으로 가정하고, 이 분포에서 평균과 분산을 출력함
하지만 현실적으로 Z의 분포 전체를 샘플링하는 것이 어렵기에 Reparmeterization Trick을 이용해 평균 + 분산*(가우시안 분포 랜덤 샘플링)을 해준 값을 Z(latent vector)로 가정함
3. Flow-based models
확률 밀도 함수를 모델링하기 위한 생성 모델로, 확률 분포의 변환 표현 Flow를 사용함
Flow: 데이터 분포를 변환하면서 확률 분포를 추론하는 방법
잠재 벡터 z의 확률 분포에 대한 일련의 역변환을 통해 데이터 x의 분포를 명시적으로 학습하며 이를 간단하게 negative log-likelihood로 해결함
생성에 활용되는 inverse mapping을 학습하기 위해 invertible function을 학습함
훈련이 비교적 안정적이고 수렴하기 쉽다는 특징이 있음
4. Diffusion
Diffusion(확산) : 특정한 데이터 패턴이 서서히 반복을 거쳐 와해되는 과정
Diffusion 모델은 학습된 데이터의 패턴을 생성해내는 역할을 하는데, 이러한 패턴 생성 과정 학습을 위해 고의적으로 패턴을 무너뜨리고(Noising)(=forward diffusion process) 이를 다시 복원하는 조건부 확률 밀도 함수를 학습함(Denoising)(=reverse diffusion process)
forward diffusion process : t-1 시점에서 t 시점으로 노이즈를 manual하게 점점 추가해나감 → 사전 정의된 guassian 분포에서 생성됨(우리가 연산을 알 수 있음)
reverse diffusion process: 수학적으로 변환하기 어려움 & 학습하는 과정 필요
noising과 denoising을 하나의 단일 step transformation으로 학습하는 것은 매우 어려운 과제이기에 여러 단계로 쪼개어진 Markov Chain으로 각 process를 구성함
VAE는 하나의 latent vector로 수행한다면, Diffusion은 sequential한 여러 개의 latent vector를 사용함
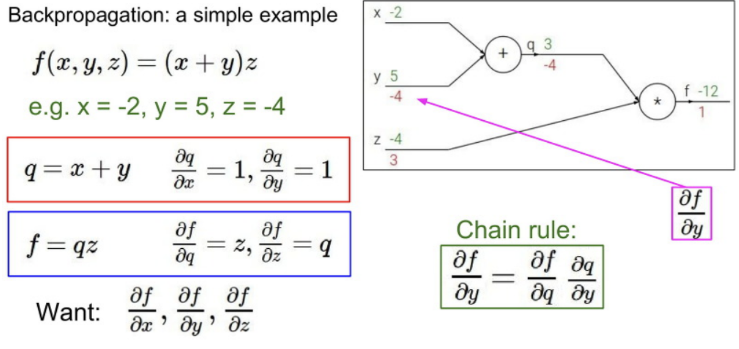
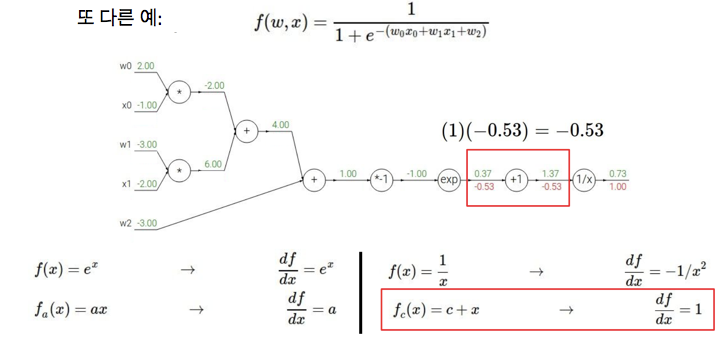
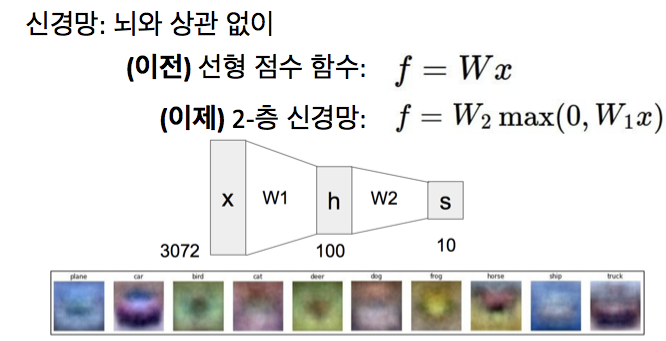
우리의 목적은 학습 데이터에 맞는 분류기에 대한 w를 찾는 것인데, 실제로는 학습 데이터에 맞추는 것이 우리의 관심사는 아님
머신러닝의 전체적인 요점은 학습 데이터를 사용해 어떤 분류기를 찾고, 그걸 테스트 데이터에 적용하는 것
w가 0이라는 것은 트레이닝 데이터에 완벽한 w라는 것인데, 결과적으로 우리에겐 train set이 아닌 test 데이터에서의 성능이 중요한 것이기 때문
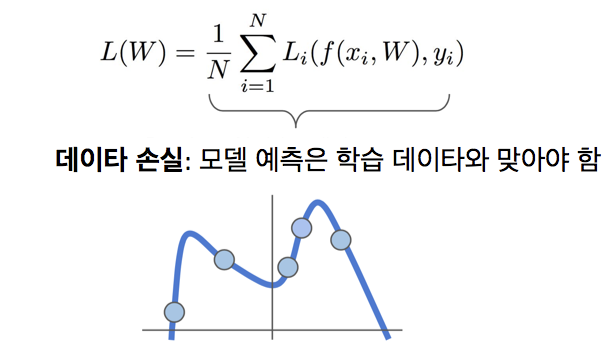
파란 점들이 데이터셋에 있다면, 이 파란 점들인 학습 데이터에 맞는 어떠한 곡선을 fit해 볼 것임
이때, 모든 학습 데이터에 대해 완벽히 분류를 하려면 매우 구불구불한 곡선을 가질 것
-> 하지만 이 성능은 중요한 것이 아님. 우리가 봐야할 것은 테스트 데이터에 대한 성능이기 때문
트렌드를 따르는 새로운 데이터가 들어오면 구불구불한 파란 선이 완전히 틀리게 되는 것임
즉, 분류기가 학습 데이터에 맞는 이 복잡한 파란 선보다는 초록 직선을 예측하는 것이 더 좋은 것
= 머신러닝에서 핵심 기본 문제
이 문제 해결을 위한 해결 방법으로 사용하는 것이 정규화(Regularization)
정규화 : 손실 함수에 정규화 항이라고 불리는 항을 더해 모델이 어느정도 단순한 W를 고르도록 유도하는 것
모델은 단순해야 테스트 데이터에서 잘 동작할 것임
오캄의 면도날 : "모든 경쟁하는 가설 중에서, 단순한 것이 최선이다" => 경쟁하는 가설들이 여럿 있을 때, 일반적으로 더 간단한 것을 선호해야 한다는 아이디어. 그것이 미래의 관찰을 일반화할 수 있는 설명임
이 직관을 머신러닝에 적용하면 표준 손실 함수는 데이터 손실(Data Loss)과 정규화 손실(Regularization Loss)이라는 두 항의 합으로 변하는 것
정규화 하이퍼파라미터인 lambda는 정규화 강도로, Data Loss과 Regularization loss의 trade-off를 조절할 수 있음
lambda는 모델을 실제로 훈련시킬 때 튜닝해야 하는 가장 중요한 것 중 하나
정규화는 여러 종류가 존재하는데, 그 중 L2 정규화를 가장 많이 사용함
1) L2 정규화
가중치 벡터 W에 대한 유클리드 norm
때로 제곱 norm 혹은 반 제곱 norm을 사용하기도 함. 미분을 없애주기 때문임
가중치 벡터의 L2(유클리드) norm에 패널티를 주는 것이 아이디어
2) L1 정규화
가중치 벡터의 L1(맨해튼) norm에 패널티를 줌
matrix W의 희소성(sparsity)를 증가시킨다는 좋은 특징이 있음
L1 정규화는 가중치 벡터의 절대값 합을 최소화하려는 특성 때문에 가중치 중 일부를 0으로 만들어 희소성을 증가시킴
데이터에 여러 특징이 있을 때, L1 정규화를 적용하면 비용 함수는 특정 특징들의 가중치를 0으로 만들어 모델을 단순화하려고 함
ex : 가중치 matrix W=[0.5,1.2,0.0,0.0,0.0,2.3] -> 6개의 특징 중에서 3개의 특징만이 중요한 역할을 하고 나머지 3개는 무시된다는 것을 의미
즉, Regularization loss를 다음과 같이 생각할 수 있음
=> 모델은 여전히 더 복잡한 모델이 될 가능성이 있으나, soft penalty인 regularization을 추가함으로써, 만약 너가 복잡한 모델을 계속 쓰고 싶으면, 이 penalty를 감수해야 할 것
모델의 복잡도 측정 방법 - L2 정규화
x : 학습 예제.4 by 1 벡터
2개의 W에서 고려 중인 상황
1) linear classification (f = Wx)의 관점 - 동일
선형 분류에서는 x와 W를 내적하는데, 이 선형 분류 관점에서 W1과 W2는 동일한 스코어 1을 제공하므로 data loss도 동일함
2) L2 regression 관점 - W2 선호
W2가 더 norm이 작기 때문
모든 요소가 골고루 영향을 미치길 바람
만약 베이지안을 쓴다면, L2 정규화는 W에 대한 Gaussian prior를 사용한 MAP 추론에 해당함
2) L1 regression 관점 - W1 선호
sparse한 solution을 고름
0이 많으면 좋다고 판단함
-> 모델과 데이터의 특성에 따라 regularization loss를 잘 설계하는 것이 중요함
멀티클래스 SVM 외에 딥러닝에서 많이 쓰이는 손실 함수로는 Multinomial Logistic Regression(softmax)가 있음
Multinomial Logistic Regression (Softmax)
Multi-class SVM loss는 스코어 자체에 대한 해석보다는 정답 클래스와 정답이 아닌 클래스들을 비교하는 형식이었음
단지 참인 점수를 원하고, 맞는 클래스의 점수가 틀린 클래스보다 커야 한다는 사실 이상으로는 점수들이 무엇을 의미하는지에 대해 얘기하지 않았음
-> Multinomial logistic regression : 스코어 자체에 추가적인 의미를 부여함
softmax 함수를 이용해 모든 점수를 얻고, 지수화해 양수로 만듦
단계 : 스코어 자체를 loss로 쓰는 것이 아니라 지수화 시켜 양수로 만듦 -> 정규화 -> log 씌움
소프트맥스 함수로 점수들을 통과시켜 클래스별 확률 분포를 계산하고, 이를 이용해 Loss를 계산함
앞의 예제에 적용해보면 아래와 같음
모두 더하면 1이 되도록 정규화 -> L_i는 -log = 소프트맥스 손실 (혹은 다항 로지스틱 회귀)
1) L_i의 최대값 & 최소값
=> 최소 손실은 0이고, 최대 손실은 무한대
우리가 원하는 확률 분포 : 맞는 클래스에는 1, 틀린 클래스에는 0
맞는 클래스 -> 로그 안의 것이 1이 되고 결국 로그 1은 0이 됨(-가 붙어도 0) = 우리가 완전히 다 맞으면 손실은 0
그러나 모든 것을 다 맞기 위해서 우리의 점수는 꽤 극단적으로 무한대를 향해서 가야 함
우리가 이 지수화와 정규화를 가지고 있기 때문에, 우리가 사실 0과 1 확률 분포를 가질 수 있는 유일한 방법은 무한대의 점수를 맞는 클래스에 주고, 마이너스의 무한대 점수를 틀린 클래스에 주는 것임
하지만 컴퓨터는 무한대를 잘 쓰지 못하기에 유한한 정밀도로 0 손실을 얻기는 사실상 불가능 (그러나 0은 이론적인 최소 손실이라고 해석해 볼 수 있음)
최대 손실은 범위가 없음
만약 우리가 맞는 클래스에 대해 0 확률 질량을 가짐 -> 0의 마이너스 로그를 갖게 됨
로그 0은 음의 무한대고, 음수 로그 0은 양의 무한대
매우 안좋지만 이걸 실제로 보진 못할 것. 이 확률이 0이되는 유일한 방법은 맞는 클래스 점수 제곱이 0이면, 이건 단지 맞는 클래스 점수가 음의 무한대일 때 가능하기 때문
결론적으로, 우리는 유한한 정확도로는 이 최소값과 최대값을 가질 수 없을 거라는 이야기임
-> 멀티클래스 SVM 문맥에서 디버깅 온전성 검사 외에 추가로 교차 검증, 혼동 행렬, 정밀도-재현율 곡선, ROC 곡선 등의 방법을 사용하여 모델의 성능을 종합적으로 평가하면 더욱 신뢰성 있는 결과를 얻을 수 있음
2) 초기화에서 w가 매우 작아서 모든 s가 0에 가깝다면 loss는 얼마인가?
- log(1/C) = log(C)
-> 소프트맥스 loss로 모델을 훈련할 때 첫번째 iteration을 확인해 봐야 함. 이게 log(C)가 아니면 무언가 문제가 있는 것이라고 판단 가능
softmax와 SVM
입력에 대해 곱해지는 W 매트릭스를 갖고 있고, 그걸로 이 점수 벡터를 만들 수 있음
이 두 손실 함수간의 차이는 우리가 나중에 정량적으로 나쁨을 측정하기 위해서 어떻게 그 점수들을 해석하는 지로 결정됨
SVM : 우리는 맞는 클래스 점수와 틀린 클래스 점수 간의 마진을 봄
소프트맥스 혹은 교차 엔트로피 손실 : 확률 분포를 계산하고 맞는 클래스의 음의 로그 확률을 봄
위의 3개의 점수를 가진다고 가정
우리가 이전에 본 예제로 다시 돌아가면, 멀티클래스 SVM 손실에서 차 점수는 다른 틀린 클래스 보다 훨씬 점수가 높았음
그 차 이미지의 점수를 약간 바꿔보는 건 멀티클래스 SVM 손실을 전혀 바꾸지 않았음
왜냐면 SVM 손실이 신경 쓰는 건 틀린클래스 점수와 비교해서 마진보다 큰 맞는 점수를 얻는 것이기 때문
소프트맥스 손실: 여러분이 맞는 클래스에 대해서 매우 높은 점수를 주더라도 항상 확률 질량을 1로 몰아가길 원함(틀린 클래스에 대해 아주 낮은 확률을 줌)
소프트맥스는 여러분이 점점 더 많은 확률 질량을 맞는 클래스 위에 쌓길 원함
맞는 클래스의 그 점수는 무한대를 향해 위로, 틀린 클래스의 점수는 아래로 음의 무한대로 밀어붙임
=> SVM은 이 데이타 포인트를 바 (bar) 위로 올려 맞는 클래스로 분류되도록 한 후엔 포기함(더이상 데이타 포인트를 상관하지 않음)
반면 소프트맥스는 계속해서 모든 데이타 포인트를 개선해서 더 나아지도록 노력함
실제로는 뭘 선택하든지 별로 큰 차이가 없고, 적어도 많은 딥러닝 어플리케이션에서는 둘은 꽤 비슷하게 동작함
Summary
x들과 y들의 데이타 셋이 존재할 때, 우리의 선형 분류기를 사용해서 input인 x로부터 점수 s를 계산하는 어떤 점수 함수를 얻음
-> 손실 함수를 사용해 우리의 예측이 그라운드 참 타겟 (ground true target) y와 비교해서 정량적으로 얼마나 나쁜지 계산함
ex : 소프트맥스, SVM이나 혹은 다른 어떤 다른 손실 함수를 사용
& 손실 함수를 정규화 항으로 개선시킴
정규화 항은 학습 데이타에 핏 (fit)하는 것과 간단한 모델을 선호하는 것 사이에서 트래이드오프 (trade-off)
=> 우리가 흔히 지도 학습이라고 부르는 것의 꽤 일반적인 개요! 이 모든걸 조합해서 최종 손실함수를 최소화하는 W를 찾으려고 하는 것
Optimization
예측 함수 f, 손실 함수, 정규화가 커지고 복잡해짐 & 신경망 사용
-> 곧장 최소값으로 데려다 주는 명확한 분석적 해답을 기대하긴 어려움
-> 실제에선 다양한 종류의 반복적 메소드를 사용함. 어떤 해답으로 시작을 해서 시간이 지남에 따라 그걸 점점 개선시킴
1) 랜덤 탐색(search)
가장 처음으로 생각해볼 수 있는 방법
단순히 W를 많이 받아 임의로 샘플링하고 그걸 손실함수에 넣음
가장 나쁜 방법
2) 경사따라가기
1차원에서의 경사 : 함수의 미분
1차원 함수 f가 있다면 스칼라 x를 받아서 어떤 커브의 높이를 돌려주고, 그 후 어떤 지점에서든지 경사를(미분값을) 계산
다변수에서의 경사 : 부분 미분의 벡터. 경사는 x와 같은 모양 가짐
경사의 각 항목 : 우리가 좌표에서 만약 그 방향으로 움직일 때 함수 f의 경사값이 무엇인가
경사 = 부분 미분한 벡터 -> 가장 크게 증가하는 방향 가리킴
반대 경사 방향 -> 가장 크게 감소하는 방향 가리짐
그 풍경에서 모든 방향으로의 경사 = 경사와 그 방향을 가리키는 단위 벡터(unit vector)와의 내적
-> 경사는 현재 지점에서 우리의 함수로의 1차 선형 근사를 제공함
경사 ∇L(W)는 손실 함수 L의 각 파라미터 W_i에 대한 편미분 값으로 구성
딥러닝에서의 경사 : 경사를 이용해 파라미터나 벡터를 반복적으로 업데이트
가장 나이브한 경사 평가 방법 = 유한 차분(infinite difference)의 방법 이용 = numerical gradient
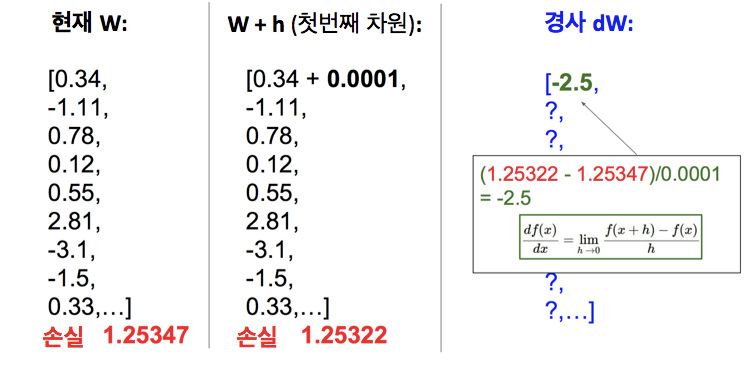
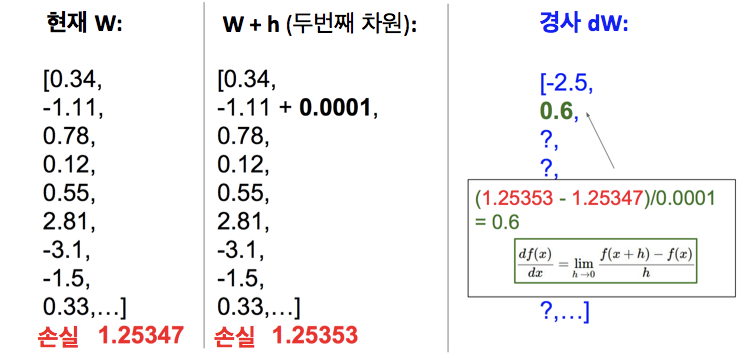
파라미터 벡터 : W
현재 손실 : 약 1.25
경사 dW의 각 항목은 W의 각 성분이 작은 무한소(infinitesimal)의 양만큼 변화할 때 그 좌표방향으로 손실이 얼마나 변할지 알려줌
-> W의 각 성분 W_i를 아주 조금 ϵ만큼 변경했을 때, 손실 함수의 변화는 아래와 같이 근사할 수 있음
이 유한한 차이를 계산할 수 있음
w를 가지고 있을 때 w의 첫번째 원소를 작은 값(h, 아래에선 0.0001)만큼 증가시키려고 함
그 후 손실 함수와 분류기 등을 이용해 손실을 다시 계산함
1) numerical gradient
첫번째 차원에서 조금 움직이면 손실은 1.2534에서 1.25322가 됨
limit definition을 사용해서 첫번째 차원의 경사에 대한 유한 차분 근사를 얻을 수 있음
두번째 차원에서 첫번째 차원을 원래 값(0.34. 0.0001을 더하기 전)으로 되돌려놓고, 두번째 방향으로 조금 움직임
다시 손실 계산하고 두번째 슬롯에서 경사에 대한 근사를 계산하기 위해 유한 차분 근사를 사용함
이 일을 계속 반복함
3번째 차원에서의 유한 차분 근사
-> 사실 끔찍한 아이디어임. 속도가 매우 느리기 때문
함수 f를 계산하는 것은 실제로 엄청 느린데, 위와 같이 10개의 항목이 아닌 수천만개의 파라미터 벡터를 가지는 합성곱 신경망이라면 하나의 경사를 얻기 위해 수억개의 함수 평가를 기다려야 함 -> 미적분을 써서 계산하는 것이 효율적! 하나의 표현식만 계산하면 되기 때문 = analytical gradient
2) analytical gradient
요약하면 numerical gradient는 간단하고 상식적임
하지만 실제에서는 사용하지 않고, 항상 분석적 경사(analytical gradient) 를 취해 사용함
numerical gradient는 유용한 디버깅 도구로 사용됨
손실과 손실의 경사를 계산하는 코드를 썼을 때, 수치적 경사를 일종의 유닛 테스트로 사용해서 확실히 자신의 분석적 경사가 맞는지 확인함
느리고 정확하지 않아서 수치적 경사 체킹을 할 땐 실제로 합리적인 시간내에 동작하도록 문제의 파라미터를 스케일 다운(scale down)해야 함
-> w를 공간의 임의의 지점에서 시작하고 음의 경사 방향을 계산하는 과정을 반복하며 최소값에 도달
-> 다음 스텝이 어디인지를 결정하기 위해 경사를 이용하는데, 이 경사 정보를 어떻게 사용해야 할 지 알려주는 업데이트 룰이 존재함
ex : adam, momentum
확률적 경사 하강(stochastic gradient descent)
전체 데이터셋에 대해 손실과 경사를 계산하기 보단 매 반복마다 미니배치(mini batch)의 학습 예제를 샘플링
미니배치의 크기는 관습적으로 2의 제곱수로 설정 ex : 32, 64, 128, ...
"확률적"인 이유 : 어떤 참 값의 기댓값의 몬테카를로 추정을 사용하기 때문
데이터의 랜덤 미니배치 샘플링 -> 미니 배치에 대한 손실과 경사 평가 -> 이 손실에 대한 추정과 이 경사의 추정에 근거해 파라미터 업데이트
Image Features
선형 분류기에서는 raw로 이미지 픽셀을 받아서 이 raw 픽셀을 선형 분류기에 그대도 input으로 넣음
-> 멀티 모달리티로 인해 좋은 방법은 아님
DNN 유행 전의 방법
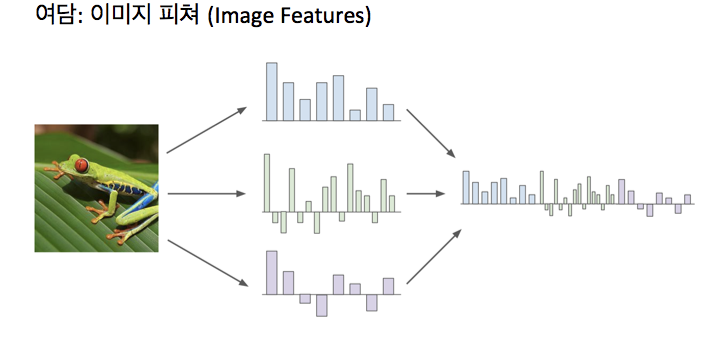
이미지를 받은 후 이미지의 다양한 피쳐 표현( 이미지에 나타난 모양과 관련한 여러 종류의 정량적인 것들 )을 계산함
-> 여러 특징 표현들을 concat시켜 하나의 feature vector로 만듦 (이미지의 feature representation이 나타남)
-> raw 픽셀 자체를 넣는 것 대신 이 이미지의 피쳐 표현(feature vector)이 선형분류기로 들어감
이미지 피쳐의 동기
Linear한 결정 경제를 그릴 방법이 없는 데이터셋의 경우 적절하게 feature transform을 거침
-> 선형으로 분리가 가능하게 바뀜
위의 경우에서는 극 좌표계(polar coordinate)로의 트랜스폼 후 선형으로 분류할 수 있게 바뀐 것임
이미지의 경우 픽셀들을 극좌표계로 바꾸는 것은 전혀 말이 안되는 일이지만 극좌표계로 변환하는 것을 일종의 특징 변환이라 생각한다면 말이 되는 것
이렇게 분류기에 넣는 것이 raw 이미지를 넣는 것보다 성능이 좋을 수 있음
-> 문제에 어떤 feature transform을 적용할 것인지 결정하는 것이 중요
특징 변환의 예로는 다음과 같음
1. Color Histogram
이미지에서 Hue color spectrum만 뽑아서 모든 픽셀을 버킷에 나눠담은 후 모든 픽셀을 이 컬러 버킷들의 하나에 매핑
-> 얼마나 많은 픽셀이 버킷에 담겼는지 셈
= 이미지가 전체적으로 어떤 색인지 관찰 가능
개구리의 예 : 초록색이 많으며 자주색이나 붉은색은 별로 없음
2. Histogram of Oriented Gradients(HoG)
이미지를 8 by 8로 픽셀을 나눔
-> 이 픽셀 지역 내에서 가장 지배적인 edge의 방향을 계산하고 edge directions를 양자화해 버킷에 넣음
-> 다양한 edge oreirentations에 대한 histogram을 계산함
=> 전체 특징 벡터는, 각각의 모든 8x8 지역들이 가진 "edge orientation에 대한 히스토그램" 이 되는 것!
컬러 히스토그램 : 이미지 전체적으로 어떤 색이 있는지 나타냄
HOG : 이미지 내에 전반적으로 어떤 edge 정보가 있는지 나타냄 & 이미지를 여러 부분으로 지역화해서, 지역적으로 어떤 edge가 존재하는지도 알 수 있음
이파리 위에 앉아있는 개구리 이미지 : 이파리들은 주로 대각선 edge를 가지고 있는데, 실제 HoG를 시각화해보면 이파리 부분에 많은 대각 edge가 있음을 볼 수 있음
HoG는 흔한 피쳐 표현이고, 객체 인식에 많이 사용됨
3. bag of words(BoW)
문장의 여러 단어의 발생 빈도를 세 특징 벡터로 사용하는 NLP에서의 직관을 이미지에 적용한 것
시각 단어(visual words) 정의가 필요함
엄청 많은 이미지를 가지고, 그 이미지들은 임의대로 조각냄 -> 그 조각들을 K-means와 같은 알고리즘으로 군집화
-> 시각 단어는 빨강색, 파란색, 노랑색과 같은 다양한 색 & 다양한 종류와 다양한 방향의 oriented edges 포착해냄
-> 시각 단어 집합인 Codebook 형성
-> 어떤 이미지가 있으면, 이 이미지에서의 시각 단어들의 발생 빈도를 통해서 이미지를 인코딩 할 수 있게 됨
이미지 분류 파이프라인
5~10년 전까지만 해도 이미지를 입력받으면 BOW나 HOG와 같은 다양한 특징 표현을 계산하고, 계산한 특징들을 한데 모아 연결해서, 추출된 그 특징들을 Linear classifier의 입력으로 사용했음
특징이 한번 추출되면 feature extractor는 classfier를 트레이닝하는 동안 변하지 않음
트레이닝 중에는 오직 Linear classifier만 훈련이 됨
CNN이나 DNN으로 넘어가보면 위와 실제로 크게 다르지 않음
유일한 차이점 : 이미 만들어 놓은 특징들을 쓰기 보다는 데이터로부터 특징들을 직접 학습하려 한다는 것 -> raw 픽셀이 CNN에 그대로 들어가고 여러 레이어를 거쳐서 데이터를 통한 특징 표현을 직접 만들어냄 -> Linear classifier만 훈련하는게 아니라 가중치 전체를 한꺼번에 학습하는 것
단어 시퀀스에 확률을 할당하게 하기 위해 가장 보편적으로 사용되는 방법은 언어 모델이 이전 단어들이 주어졌을 때 다음 단어를 예측하도록 하는 것
> 언어 모델링
주어진 단어들로부터 아직 모르는 단어를 예측하는 작업
= 언어 모델이 이전 단어들로부터 다음 단어를 예측하는 일
> 단어 시퀀스의 확률 할당
언어 모델은 확률을 통해 보다 적절한 문장을 판단함
기계 번역 : P(나는 버스를 탔다) > P(나는 버스를 태운다)
오타 교정 : 선생님이 교실로 부리나케 P(달려갔다) > P(잘려갔다)
음성 인식 : P(나는 메롱을 먹는다) < P(나는 메론을 먹는다)
> 단어 시퀀스의 확률
하나의 단어를 w, 단어 시퀀스를 대문자 W라고 한다면, n개의 단어가 등장하는 단어 시퀀스 W의 확률은
전체 단어 시퀀스 W의 확률은 모든 단어가 예측되고 나서야 알 수 있으므로 단어 시퀀스의 확률은 다음과 같음
10-2. 통계적 언어 모델(Statistical Language Model, SLM)
각 단어는 문맥이라는 관계로 인해 이전 단어의 영향을 받아 나온 단어이고, 모든 단어로부터 하나의 문장이 완성됨
-> 문장의 확률을 구하고자 조건부 확률을 사용함
문장의 확률을 구하기 위해 각 단어에 대한 예측 확률들 곱함
카운트 기반의 접근
SLM은 이전 단어로부터 다음 단어에 대한 확률을 카운트에 기반한 확률 계산으로 구함
An adorable little boy가 나왔을 때 is가 나올 확률은
예를 들어 기계가 학습한 코퍼스 데이터에서 An adorable little boy가 100번 등장했는데 그 다음에 is가 등장한 경우는 30번이라고 하면, 이 경우 𝑃(is|An adorable little boy)는 30%이 됨
카운트 기반 접근의 한계 - 희소 문제(Sparsity Problem)
> 희소 문제(sparsity problem)
충분한 데이터를 관측하지 못하여 언어를 정확히 모델링하지 못하는 문제
SLM의 한계는 훈련 코퍼스에 확률을 계산하고 싶은 문장이나 단어가 없을 수 있다는 점 & 확률을 계산하고 싶은 문장이 길어질수록 갖고있는 코퍼스에서 그 문장이 존재하지 않을 가능성이 높음(카운트할 수 없을 가능성이 높음)
희소 문제를 완화하는 방법으로 n-gram 언어 모델이나 스무딩, 백오프와 같은 여러 일반화 기법을 사용함
하지만 근본적인 해결책은 되지 못하였고, 이러한 한계로 인해 언어 모델의 트렌드는 인공 신경망 언어 모델로 넘어가게 됨
10-3. N-gram 언어 모델(N-gram Language Model)
카운트에 기반한 통계적 접근을 사용하고 있으므로 SLM의 일종.
다만, 앞서 배운 언어 모델과는 달리 이전에 등장한 모든 단어를 고려하는 것이 아니라 일부 단어만 고려하는 접근 방법을 사용함
다음과 같이 참고하는 단어들을 줄이면 카운트할 수 있을 가능성을 높일 수 있음
An adorable little boy가 나왔을 때 is가 나올 확률을 그냥 boy가 나왔을 때 is가 나올 확률로 생각
-> 기준 단어의 앞 단어를 전부 포함해서 카운트하는 것이 아니라, 앞 단어 중 임의의 개수만 포함해 카운트해 근사하면 해당 단어의 시퀀스를 카운트할 확률이 높아짐
N-gram
임의의 개수를 정하기 위한 기준을 위해 사용하는 것이 n-gram.
n: n개의 연속적인 단어 나열 의미
갖고 있는 코퍼스에서 n개의 단어 뭉치 단위로 끊어서 이를 하나의 토큰으로 간주함
n이 1일 때는 유니그램(unigram), 2일 때는 바이그램(bigram), 3일 때는 트라이그램(trigram)이라고 명명하고 n이 4 이상일 때는 gram 앞에 그대로 숫자를 붙여서 명명
1-gram, 2-gram, 3-gram이라고 하기도 함
An adorable little boy is spreading smiles에서 각 n에 대한 n-gram
n = 4라고 한 4-gram을 이용한 언어 모델을 사용한다고 하면, spreading 다음에 올 단어를 예측하는 것은 n-1에 해당되는 앞의 3개의 단어만을 고려함
만약 갖고있는 코퍼스에서 boy is spreading가 1000번 등장했고, boy is spreading insults가 500번 등장했으며, boy is spreading smiles가 200번 등장했을 때 boy is spreading 다음에 insults가 등장할 확률과 smiles가 등장할 확률은 아래와 같음
따라서 insults가 더 맞다고 판단할 수 있음
N-gram Language Model의 한계
: n-gram은 앞의 단어 몇 개만 보다 보니 의도하고 싶은 대로 문장을 끝맺음하지 못하는 경우가 생김
-> 전체 문장을 고려한 언어 모델보다 정확도가 떨어질 수밖에 없음
1) 희소 문제 (Sparsity Problem)
현실적으로 코퍼스에서 카운트 할 수 있는 확률을 높일 수는 있었지만, n-gram 언어 모델도 여전히 n-gram에 대한 희소 문제가 존재함
2) n을 선택하는 것은 trade-off 문제
n을 크게 선택하면 실제 훈련 코퍼스에서 해당 n-gram을 카운트할 수 있는 확률은 적어지므로 희소 문제는 점점 심각해짐
또한 n이 커질수록 모델 사이즈가 커진다는 문제점도 존재함
-> n은 최대 5를 넘겨서는 안된다고 권장됨
10-4. 한국어에서의 언어 모델(Language Model for Korean Sentences)
한국어의 특징
1) 한국어는 어순이 중요하지 않음
-> 단어 순서를 뒤죽박죽으로 바꾸어놔도 의미가 전달되기에 확률에 기반한 언어 모델이 제대로 다음 단어를 예측하기 어려움
2) 교착어임
조사 존재 -> 단어 하나에도 다양한 경우가 존재함
따라서 토큰화를 통해 접사나 조사 등을 분리하는 것은 중요한 작업이 되기도 함
3) 띄어쓰기가 제대로 지켜지지 않음
띄어쓰기를 제대로 하지 않아도 의미가 전달되고, 띄어쓰기 규칙 또한 상대적으로 까다로운 언어임 -> 띄어쓰기가 제대로 지켜지지 않는 경우가 많음
10-5. 펄플렉서티(Perplexity, PPL)
: 모델 내에서 자신의 성능을 수치화하여 결과를 내놓는 언어 모델의 평가 방법
두 모델의 성능을 비교하고자, 일일히 모델들에 대해서 실제 작업을 시켜보고 정확도를 비교하는 작업은 공수가 너무 많이 드는 작업이기에 사용함
PPL은 수치가 높으면 좋은 성능을 의미하는 것이 아니라, '낮을수록' 언어 모델의 성능이 좋다는 것을 의미함
분기 계수(Branching factor)
PPL은 선택할 수 있는 가능한 경우의 수를 의미하는 분기계수(branching factor)임
PPL은 이 언어 모델이 특정 시점에서 평균적으로 몇 개의 선택지를 가지고 고민하고 있는지를 의미함
Ex) PPL이 10인 경우
: 해당 언어 모델은 테스트 데이터에 대해서 다음 단어를 예측하는 모든 시점(time step)마다 평균 10개의 단어를 가지고 어떤 것이 정답인지 고민하고 있다고 볼 수 있음
: 각각 규칙1과 규칙2에 따라서 home-based는 하나의 토큰으로 취급하고 있으며, dosen't의 경우 does와 n't는 분리되었음
문장 토큰화(Sentence Tokenization)
: 갖고있는 코퍼스 내에서 문장 단위로 구분하는 작업
보통 갖고있는 코퍼스가 정제되지 않은 상태라면, 코퍼스는 문장 단위로 구분되어 있지 않아서 이를 사용하고자 하는 용도에 맞게 문장 토큰화가 필요할 수 있음
NLTK : sent_tokenize
한국어는 KSS 이용
한국어에서의 토큰화의 어려움
영어는 New York과 같은 합성어나 he's 와 같이 줄임말에 대한 예외처리만 한다면, 띄어쓰기(whitespace)를 기준으로 하는 띄어쓰기 토큰화를 수행해도 단어 토큰화가 잘 작동함
-> 거의 대부분의 경우에서 단어 단위로 띄어쓰기가 이루어지기 때문에 띄어쓰기 토큰화와 단어 토큰화가 거의 같기 때문
하지만 한국어는 영어와는 달리 띄어쓰기만으로는 토큰화를 하기에 부족함
-> 어절 토큰화는 한국어 NLP에서 지양되고 있기 때문. 이는 어절 토큰화와 단어 토큰화는 같지 않기 때문임. 그 근본적인 이유는 한국어가 영어와는 다른 형태를 가지는 언어인 교착어라는 점에서 기인함
어절 : 띄어쓰기 단위가 되는 단위
교착어 : 조사, 어미 등을 붙여서 말을 만드는 언어
1) 교착어의 특성
그 -> '그가', '그에게', '그를', '그와', '그는'과 같이 다양한 조사가 '그'라는 글자 뒤에 띄어쓰기 없이 바로 붙을 수 있음
자연어 처리를 하다보면 같은 단어임에도 서로 다른 조사가 붙어서 다른 단어로 인식이 되면 자연어 처리가 힘들고 번거로워지는 경우가 많음
대부분의 한국어 NLP에서 조사는 분리해줄 필요가 존재함
즉, 띄어쓰기 단위가 영어처럼 독립적인 단어라면 띄어쓰기 단위로 토큰화를 하면 되겠지만 한국어는 어절이 독립적인 단어로 구성되는 것이 아니라 조사 등의 무언가가 붙어있는 경우가 많아서 이를 전부 분리해줘야 한다는 의미
한국어 토큰화에서는 형태소(morpheme) 개념 이해가 필수적임
2) 형태소
: 뜻을 가진 가장 작은 말의 단위
자립 형태소 : 접사, 어미, 조사와 상관없이 자립하여 사용할 수 있는 형태소. 그 자체로 단어가 됨. 체언(명사, 대명사, 수사), 수식언(관형사, 부사), 감탄사 등이 있음
의존 형태소 : 다른 형태소와 결합하여 사용되는 형태소. 접사, 어미, 조사, 어간을 의미
Ex) 문장 : 에디가 책을 읽었다
띄어쓰기 단위 토큰화 -> ['에디가', '책을', '읽었다']
하지만 이를 형태소 단위로 분해하면 다음과 같음
자립 형태소 : 에디, 책
의존 형태소 : -가, -을, 읽-, -었, -다
한국어에서 영어에서의 단어 토큰화와 유사한 형태를 얻으려면 어절 토큰화가 아니라 형태소 토큰화를 수행해야함
3) 한국어는 띄어쓰기가 영어보다 잘 지켜지지 않는다.
한국어는 띄어쓰기가 지켜지지 않아도 글을 쉽게 이해할 수 있는 언어
-> 수많은 코퍼스에서 띄어쓰기가 무시되는 경우가 많아 자연어 처리가 어려워졌음
품사 태깅(Part-of-speech tagging)
: 단어 토큰화 과정에서 각 단어가 어떤 품사로 쓰였는지를 구분해놓는 것
단어는 표기는 같지만 품사에 따라서 단어의 의미가 달라지기도 하기에, 결국 단어의 의미를 제대로 파악하기 위해서는 해당 단어가 어떤 품사로 쓰였는지 보는 것이 주요 지표가 될 수도 있기 때문
NLTK : Penn Treebakn POS Tags라는 기준을 이용해 품사를 태깅함
KoNLPy : 한국어 자연어 처리에 사용되는 파이썬 패키지 - 형 태소 분석기: Okt(Open Korea Text), 메캅(Mecab), 코모란(Komoran), 한나눔(Hannanum), 꼬꼬마(Kkma) 존재
morphs : 형태소 추출
pos : 품사 태깅(Part-of-speech tagging)
nouns : 명사 추출
3-2. 텍스트 데이터의 정제와 정규화
코퍼스에서 용도에 맞게 토큰을 분류하는 작업을 토큰화(tokenization)라고 하며, 토큰화 작업 전, 후에는 텍스트 데이터를 용도에 맞게 정제(cleaning) 및 정규화(normalization)하는 일이 항상 함께함
정제(cleaning) : 갖고 있는 코퍼스로부터 노이즈 데이터를 제거함
정규화(normalization) : 표현 방법이 다른 단어들을 통합시켜서 같은 단어로 만들어줌
완벽한 정제 작업은 어려운 편이라서, 대부분의 경우 이 정도면 됐다.라는 일종의 합의점을 찾기도 함
> 규칙에 기반한 표기가 다른 단어들의 통합
ex) USA와 US는 같은 의미를 가지므로 하나의 단어로 정규화
> 대, 소문자 통합
영어권 언어에서 대, 소문자를 통합하는 것은 단어의 개수를 줄일 수 있는 또 다른 정규화 방법임
물론 무작정 통합해서는 안됨. 미국을 뜻하는 단어 US와 우리를 뜻하는 us는 구분되어야 함 & 회사 이름(General Motors)나, 사람 이름(Bush) 등은 대문자로 유지되는 것이 옳음
> 불필요한 단어의 제거
정제 작업에서 제거해야하는 노이즈 데이터(noise data)는 자연어가 아니면서 아무 의미도 갖지 않는 글자들(특수 문자 등)을 의미하기도 하지만, 분석하고자 하는 목적에 맞지 않는 불필요 단어들을 노이즈 데이터라고 하기도 함
1) 등장 빈도가 적은 단어
2) 길이가 짧은 단어 (영어권 언어)
영어 단어의 평균 길이는 6~7 정도 -> 갖고 있는 텍스트 데이터에서 길이가 1인 단어를 제거하는 코드를 수행하면 대부분의 자연어 처리에서 의미를 갖지 못하는 단어인 관사 'a'와 주어로 쓰이는 'I'가 제거됨
> 정규 표현식(Regular Expression)
얻어낸 코퍼스에서 노이즈 데이터의 특징을 잡아낼 수 있다면, 정규 표현식을 통해 이를 제거할 수 있는경우가 많음
ex) HTML 문서로부터 가져온 코퍼스라면 문서 여기저기에 HTML 태그가 존재
3-3. 불용어(Stopwords)
: 문장에서는 자주 등장하지만 실제 의미 분석을 하는데는 거의 기여하는 바가 없는 경우
Ex) I, my, me, over, 조사, 접미사 같은 단어들
stopwords.words("english")는 NLTK가 정의한 영어 불용어 리스트를 리턴함
NLTK를 통해 불용어 제거하기
example = "Family is not an important thing. It's everything."
stop_words = set(stopwords.words('english'))
word_tokens = word_tokenize(example)
result = []
for word in word_tokens:
if word not in stop_words:
result.append(word)
print('불용어 제거 전 :',word_tokens)
print('불용어 제거 후 :',result)
from nltk.tokenize import RegexpTokenizer
text = "Don't be fooled by the dark sounding name, Mr. Jone's Orphanage is as cheery as cheery goes for a pastry shop"
tokenizer1 = RegexpTokenizer("[\w]+")
tokenizer2 = RegexpTokenizer("\s+", gaps=True)
print(tokenizer1.tokenize(text))
print(tokenizer2.tokenize(text))
tokenizer2의 결과는 위의 tokenizer1의 결과와는 달리 아포스트로피나 온점을 제외하지 않고 토큰화가 수행된 것 확인 가능
\w+ : 문자 또는 숫자가 1개 이상인 경우
+는 최소 1개 이상의 패턴을 찾아낸다는 의미
\s+ : 공백을 찾아내는 정규표현식
gaps=true : 해당 정규 표현식을 토큰으로 나누기 위한 기준으로 사용한다는 의미
만약 gaps=True라는 부분을 기재하지 않는다면, 토큰화의 결과는 공백들만 나오게 됨
3-5. 전처리 실습
자연어 처리는 일반적으로 토큰화, 단어 집합 생성, 정수 인코딩, 패딩, 벡터화의 과정을 거침
단어 집합(vocabuary) : 중복을 제거한 텍스트의 총 단어의 집합(set)
패딩(padding) : 길이가 다른 문장들을 모두 동일한 길이로 바꿔주는 작업. 정해준 길이로 모든 샘플들의 길이를 맞춰주되, 길이가 정해준 길이보다 짧은 샘플들에는 'pad' 토큰을 추가하여 길이를 맞춰줌
max_len = max(len(l) for l in encoded)
print('리뷰의 최대 길이 : %d' % max_len) # 63
print('리뷰의 최소 길이 : %d' % min(len(l) for l in encoded)) # 1
print('리뷰의 평균 길이 : %f' % (sum(map(len, encoded))/len(encoded))) # 13.9
가장 길이가 긴 리뷰의 길이 = 63 -> 모든 리뷰의 길이를 63으로 통일
for line in encoded:
if len(line) < max_len: # 현재 샘플이 정해준 길이보다 짧으면
line += [word_to_index['pad']] * (max_len - len(line)) # 나머지는 전부 'pad' 토큰으로 채움
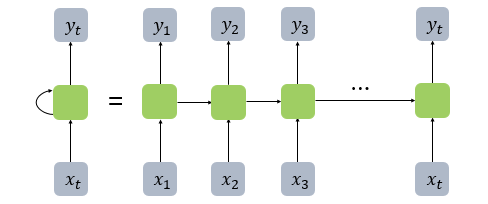
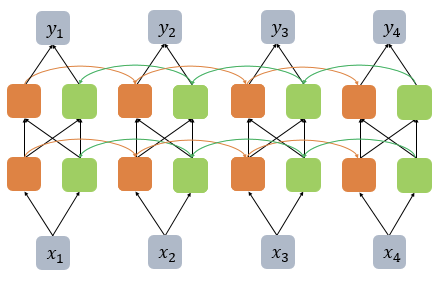
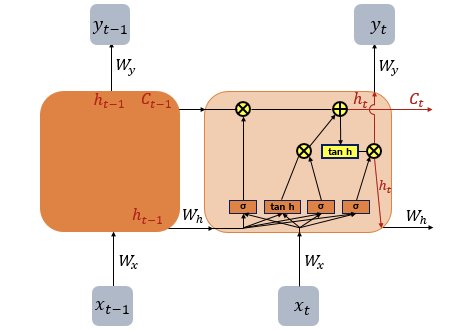
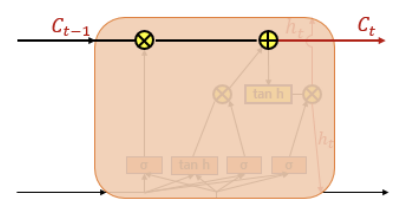
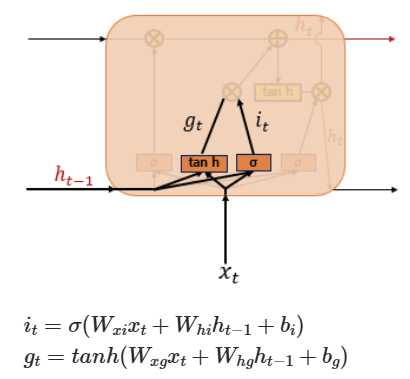
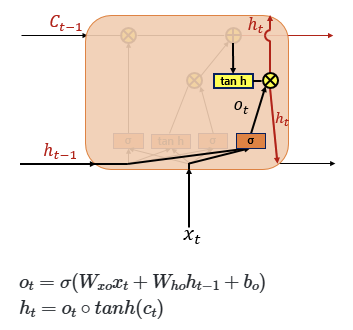
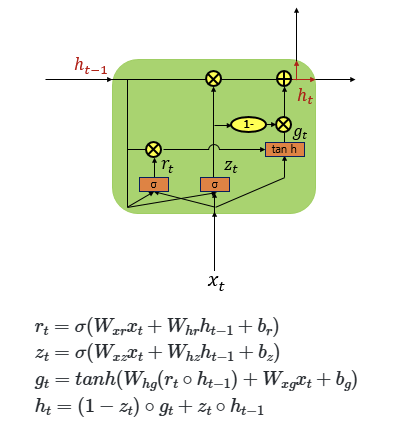
피드 포워드 신경망과(Feed Forward Neural Network) 달리 은닉층의 노드에서 활성화 함수를 통해 나온 결과값을 출력층 방향으로도 보내면서, 다시 은닉층 노드의 다음 계산의 입력으로 보내는 특징 가짐
피드 포워드 신경망 : 은닉층에서 활성화 함수를 지난 값이 오직 출력층 방향으로만 향하는 신경망
x : 입력층의 입력 벡터
y : 출력층의 출력 벡터
b : 편향 (그림에서는 생략됨)
t : 현재 시점
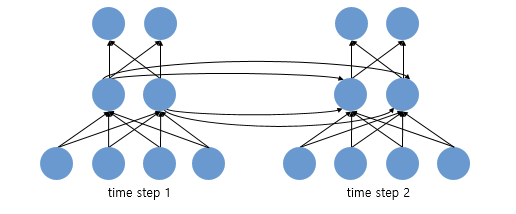
cell : 은닉층에서 활성화 함수를 통해 결과를 내보내는 역할을 하는 노드. 메모리 셀 또는 RNN 셀이라고도 표현함
은닉층의 메모리 셀은 각각의 시점(time step)에서 바로 이전 시점에서의 은닉층의 메모리 셀에서 나온 값을 자신의 입력으로 사용 = 재귀적 활동
RNN의 다른 표현
RNN의 뉴런 단위 시각화
위의 그림은 입력 벡터의 차원이 4, 은닉 상태의 크기가 2, 출력층의 출력 벡터의 차원이 2인 RNN이 시점이 2일 때의 모습
뉴런 단위로 해석하면, 입력층의 뉴런 수는 4, 은닉층의 뉴런 수는 2, 출력층의 뉴런 수는 2
은닉 상태(hidden state)
메모리 셀이 출력층 방향으로 또는 다음 시점 t+1의 자신에게 보내는 값
t 시점의 메모리 셀은 t-1 시점의 메모리 셀이 보낸 은닉 상태값을 t 시점의 은닉 상태 계산을 위한 입력값으로 사용함
RNN의 종류
RNN은 입력과 출력의 길이를 다르게 설정 가능함
일 대 다 :하나의 입력에 대해 여러 개의 출력 ex) 이미지 캡셔닝
다 대 일 : 단어 시퀀스에 대해 하나의 출력 ex) 감성 분류, 스팸 메일 분류
다 대 다 : 입력 문장으로부터 대답 문장 출력 ex) 챗봇, 번역기, 품사 태깅
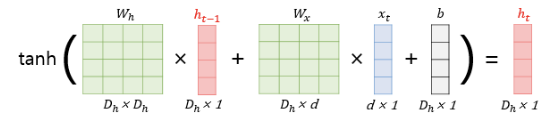
RNN 수식
h_t : 현 시점 t에서의 은닉 상태값
W_x : 입력층에서 입력 값을 위한 가중치
W_h : 이전 시점 t-1의 은닉 상태값인 h_t-1을 위한 가중치
h_t 계산을 위한 활성화 함수로 주로 tanh가 많이 사용되지만, ReLU로 바꿔 사용하는 시도도 존재함
y_t 계산을 위한 활성화 함수로는 이진 분류의 경우 시그모이드 함수를, 다양한 카테고리 중 선택하는 문제라면 소프트 맥스함수를 사용
RNN에서의 입력 x_t는 대부분의 경우 단어 벡터로 간주할 수 있는데, 단어 벡터의 차원을 d, 은닉 상태의 크기를 D_h라고 하면 각 벡터와 행렬 크기는 다음과 같다.
파이썬 pseudocode
메모리 셀에서 은닉 상태를 계산하는 식 구현
hidden_state_t = 0 # 초기 은닉 상태를 0(벡터)로 초기화
for input_t in input_length: # 각 시점마다 입력을 받는다.
output_t = tanh(input_t, hidden_state_t) # 각 시점에 대해서 입력과 은닉 상태를 가지고 연산
hidden_state_t = output_t # 계산 결과는 현재 시점의 은닉 상태가 된다.
hidden_state_t : t시점의 은닉 상태
input_length : 입력 데이터의 길이. 이 경우 입력 데이터는 총 시점의 수(timesteps)이 됨
input_t : t 시점의 입력값
각 메모리 셀은 각 시점마다 input_t와 hidden_state_t(이전 상태의 은닉 상태)를 입력으로 활성화 함수인 tanh를 통해 현 시점의 hidden_state_t를 계산한다.
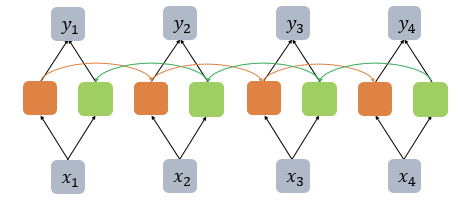
양방향 RNN
RNN이 과거 시점(time step)의 데이터들을 참고해서, 찾고자하는 정답을 예측하지만 실제 문제에서는 과거 시점의 데이터만 고려하는 것이 아니라 향후 시점의 데이터에 힌트가 있는 경우도 많음
-> 이전 시점의 데이터뿐만 아니라, 이후 시점의 데이터도 힌트로 활용하기 위해서 고안된 것이 양방향 RNN
이미지를 분류할 때, 이미지(ex: 고양이)를 input으로 받고, 시스템은 어떤 미리 정해진 카테고리나 레이블을 알고 있음
-> 컴퓨터는 그림을 보고 정해진 카테고리 레이블로 지정함
컴퓨터는 엄청난 숫자 그리드로 이미지를 표현함
위의 이미지는 800 * 600 pixel인데, 각 픽셀은 3가지의 숫자로 표현되어 픽셀에 대한 빨강, 초록, 파랑 값을 줌
컴퓨터에게는 단지 큰 그리드 숫자일 뿐이기에 이 숫자에서 고양이 성질을 끌어내기는 어려움
=> 위의 문제를 "의미적 차이(semantic gap)"라 함
고양이라는 생각(혹은 라벨)은 사람이 부여한 의미적 라벨이므로 고양이라는 의미적 아이디어와 컴퓨터가 보는 이 픽셀 값 사이엔 엄청난 차이가 존재하는 것
이미지 분류를 할 때는 다양한 챌린지들이 존재함
그림은 매우 작은 변화로도 전체적으로 픽셀이 바뀌는데, 이미지에는 여러 챌린지들이 나타날 수 있음
1) 시점 변화
ex : 같은 고양이를 찍어도 고양이가 가만히 앉아 있기만 하지는 않음. 카메라를 다른 방향으로 움직이면 그리드에서 모든 픽셀 값이 완전히 달라짐. 그러나 우리 알고리즘은 같은 고양이를 나타내야 하므로, 이러한 변화에도 견고해야 함
2) 조명, 형태 변화
ex : 장면 마다 다른 조명 조건일 경우에도 알고리즘은 동작해야 하고, 물체가 형태(포즈)를 바꿨을 경우에도 동작해야 함
3) 가림
ex: 고양이를 일부만 보게 되는 경우도 존재함
4) 배경 변화
ex: 배경이 어수선할 경우도 존재함
5) 클래스 내 변화
ex) 고양이다움이 여러 다양한 시각적 모습에 걸쳐 나타날 수 있음. 고양이는 다양한 모양과 크기와 색깔과 나이로 나타나기에 이러한 변화에도 알고리즘은 대응할 수 있어야 함
2. Image Classifier
숫자 리스트 정렬과는 달리, 고양이나 다른 클래스 인식을 위한 명확한 명시적인 알고리즘은 존재하지 않음
이러한 직관적인 감각을 만드는 혹은 어떻게 이런 객체를 인식할지에 대한 알고리즘은 없음
비주얼 인식에 있어서 중요한 것은 edge임
-> 이미지의 엣지를 계산해 다양한 코너와 경계를 분류해보려는 시도가 존재했음
하지만 이러한 알고리즘은 매우 불안정하고, 확장 가능한 방법이 아니기에 잘 동작하지 않는 걸로 판명이 남
-> 인식 작업을 훨씬 더 자연스럽게 확장할 수 있는 알고리즘과 메소드를 생각해내 모든 물체를 인식하려고 함
-> data-driven(데이터 추진) 접근 방법 아이디어 이용
Data-driven Approach 방법
: 딥러닝보다 훨씬 일반적인 아이디어임
고양이에게 필요한 규칙들, 강아지에게 필요한 규칙들을 만드는것이 아니라, 그냥 엄청나게 방대한 고양이 사진, 강아지 사진을 컴퓨터한테 제시하고, Machine Learning Classifier을 학습시키는 것
1) 이미지와 레이블로 된 데이터셋을 모음
: 인터넷에서 다양한 카테고리에 대한 매우 많은 이미지를 모음
2) 머신 러닝을 사용해 classifier를 훈련시킴
: 위의 데이터셋을 가지면, 머신러닝 분류기를 훈련시킴
3) classifier를 이용해 새로운 이미지 판별
: 학습 모델을 사용해 새로운 이미지에 적용해봄
이때 두개의 함수가 존재하는데, 하나는 학습이라 이미지와 레이블을 입력받아 모델을 출력하는 것이고, 다른 하나는 모델을 받아 이미지에 대한 예측을 수행하는 함수임
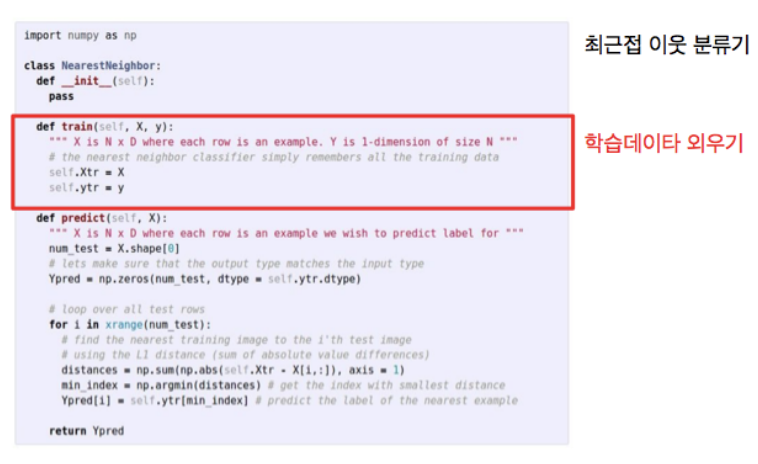
NN (Nearest Neighbor Classifier) - Data-driven Approach 방법 중 가장 단순한 분류기
1) 훈련 단계 : 학습 데이터를 단순 암기함
2) 예측 단계 : 새 이미지를 받아 학습 데이터 중 그것과 가장 비슷한 것을 찾아 그 이미지의 레이블로 예측함
구체적으로 CIFAR 10이라는 데이터셋으로 살펴볼 수 있는데, 아래와 같음
NN 알고리즘을 적용하면 학습 데이터의 가장 비슷한 예를 찾을 수 있음
가장 가까운 예의 레이블을 학습 셋에서 확인할 수 있고, 그럼 테스트 이미지가 개라고 이야기하는 것
-> 테스트 이미지를 받으면 모든 학습 이미지와 비교해야 하는데, 한 쌍의 이미지가 주어지면 그걸 어떻게 비교할 수 있을까?
=> 비교 함수를 이용함 - L1 거리, L2 거리
L1 거리(맨해튼 거리)
L1 거리 (맨해튼 거리) - 이미지 비교에 쓸 수 있는 가장 간단하고 쉬운 아이디어
: 이미지 내의 각각의 픽셀을 비교함
ex :픽셀 값은 테스트 이미지의 왼쪽 위 픽셀 값에서 학습 이미지의 왼쪽 위 값을 뺀 후 절대값을 취함. 이 과정으로 두 이미지의 차이가 구해지고, 모든 차이를 더하는 것
학습 데이터를 외우기만 하면 되기에 학습 함수는 간단한 형태임
테스트 시에는 테스트 이미지를 받아서 이 학습 예들과 L1 거리 함수를 이용해 비교함
그 후 학습 데이터셋에서 가장 비슷한 예를 찾음
한 가지 짚고 넘어가야 할 점은, 위 코드에서 시간 복잡도가 train에서보다 predict에서 더 많이 걸린다는 것임
학습은 O(1), 테스트는 데이터셋 N개의 예에 대해 테스트 이미지와 비교해야 하므로 O(N)
-> 실제로 우리가 바라는 것은 학습시에는 느리고, 테스트 시에는 빠른 것임. 따라서 NN은 우리의 바람과는 반대
또한 위의 가장 왼쪽 사진의 가운데 노란 점처럼 노이즈와 같은 부분들이 존재할 수 있다는 문제점이 존재함
= 결정 경계가 robust하지 않음
-> NN 알고리즘을 일반화한 KNN 알고리즘이 등장
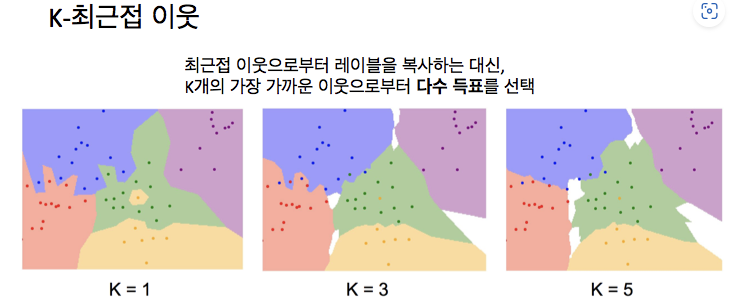
KNN (K-Nearest Neighbor Classifier) 알고리즘
하나의 최근접 이웃을 찾기 보다 거리 매트릭에 따라 K개의 최근접 이웃을 찾아서 투표를 진행하고, 가장 많은 표를 가진 이웃이 예측값이 됨
K=3일 때, 녹색 안에 있는 노란 점이 그 주변 영역을 노란색으로 만들지 않음 & 빨강과 파란색의 길게 튀어나온 부분들이 부드럽게 없어지기 시작함
K=5일 때, 파랑과 빨강 사이의 결정 경계(decision boundary)가 매우 부드러워지고 좋아짐 -> KNN 분류기를 쓸 땐 1보다 큰 어떤 K값 사용해야 결정 경계가 부드러워지고 결과가 좋아짐 = 점점 robust 해짐
*) 컴퓨터 비전에서 이미지를 생각할 때 아래의 관점으로 이해해보는 게 tip
1) 이미지를 고차원 공간의 하나의 점이라 생각하기
2) 구체적인 이미지를 보는 것. 이미지 자체로 생각하기 - 이미지의 픽셀들을 고차원 벡터로 생각할 수 있기 때문
위 두가지 관점 사이에서 왔다 갔다하는 것이 좋음
L2 거리(유클리드 거리)
제곱의 합에 제곱근을 구한 거리
L1 거리 : 픽셀의 차이를 절대값으로 더함
다른 거리 미터법을 쓴다는 건 다른 가정을 한다는 의미임
= 근간에 깔려 있는 기하학 혹은 위상 공간에서 예상하는 가정이 다르다는 것
L1 거리 : 원점을 중심으로 한 사각형 모양 & 그 사각형 위의 각점은 원점으로부터 같은 거리임
L1 거리에서는 좌표 프레임을 회전하면 L1 거리 점들간의 거리는 변화함 -> 우리의 좌표 시스템 선택에 의존적임
L2 거리 : 원 모양
L2 거리에서 좌표 프레임이 어떻게 회전하든 거리가 같음 -> 좌표 프레임을 변경하는 건 상관이 없음
=> 만약 입력 피쳐 (feature)의 벡터의 각 항목이 작업에 중요한 의미를 가진다면, L1이 자연스럽게 맞는 것일 수 있고, 만약 공간에서의 포괄적인 벡터라면, 혹은 어떤 벡터의 각 항목의 의미를 모른다면, L2가 좀 더 자연스러울 수 있음
다른 거리 미터법을 사용해서, K-최근접 이웃을 벡터나 이미지만이 아니라 매우 다양한 타입의 데이타로 일반화할 수 있음
ex : 텍스트 조각을 분류하고 싶다고 할 때 KNN을 사용하기 위해서 해야 할 건, 두 단락이나 두 문장 사이의 거리 거리 함수를 정의하는 것임. 단지 다른 거리 미터법을 지정하는 것만으로 이 알고리즘을 매우 일반적으로 만들어서 근본적으로 모든 데이타 타입에 적용할 수 있게 됨
KNN은 단순한 알고리즘이지만, 새로운 문제를 볼 때, 일반적으로 제일 처음 해볼 수 있는 것임
다른 거리 미터법을 골랐을 때의 기하학적 차이
L1 : 좌표축을 따라 그어지는 경향(L1은 좌표축에 의존적이기 때문)
L2 : 좌표축을 상관하지 않고 경계가 자연스럽게 그려지고 있음
하이퍼 파라미터
K, 거리 미터법 등을 하이퍼 파라미터라 할 수 있음
학습하기보다는 지정해야 하는 알고리즘에 관한 선택값. 문제에 따라 매우 다르기에 먼저 값들을 시도해보고 뭐가 제일 잘 되는지 봐야 함
하이퍼 파라미터 설정의 아이디어
1) 데이터에 대해 최고의 정확도 혹은 성능을 내는가
: 가장 나쁜 아이디어라 할 수 있음. K=1이면 학습 데이터에서 항상 완벽하게 동작하기 때문임
2) 데이터를 훈련과 테스트로 나누고, 테스트 데이터에서 가장 잘 동작하는 하이퍼파라미터 고르기
: 나쁨. 새로운 데이터에서 알고리즘이 어떻게 동작할 지 알 수 없기 때문
3) 데이터를 훈련, 검증, 테스트로 나누고, 검증에서 가장 잘 동작하는 하이퍼 파라미터로 테스트 평가
: 가장 많이 사용되는 방법. 데이터의 대부분을 훈련 셋에 넣고, 검증 셋과 테스트 셋을 만드는 것
모든 개발과 디버깅을 한 후, 검증 셋에서 제일 잘 되는 분류기를 테스트 셋에서 돌림. 이 결과가 알고리즘이 보지 않은 데이터에 대해 어떻게 동작할 지 얘기해줌
4) 교차 검증
데이터셋 중에 마지막 부분을 테스트 셋으로 하고 나머지를 하나의 검증 세트와 훈련 세트 파티션으로 하기 보다, 여러 개로 나누는 것
-> 어떤 부분이 검증 셋이 될지 고르는 것을 반복함
주로 작은 데이터셋에서 사용됨. 딥러닝에서는 별로 사용되지 않음
실제로 딥러닝에서는 큰 모델을 훈련할 때 컴퓨팅 비용이 비싸기 때문
KNN을 이미지에 사용하지 않는 이유
1) KNN은 테스트시 너무 느리다는 문제가 존재함. 우리가 원하는 것은 테스트시가 더 빠른 것
2) L1, L2 거리가 이미지간 거리 척도로 적절하지 않음
이 일종의 벡터 거리 함수는 이미지들에 있어서 사람의 인식의 유사성과 일치하지 않기에 사람이 이미지 차이를 인식하는 것과는 다름
ex: 아래 사진의 왼쪽 3개는 유클리드 거리를 계산했을 때 모두 같은 L2 거리를 가짐 -> 이것으로 이미지 간의 인식적 차이를 잡아내는 것은 좋은 결과를 내지 못함
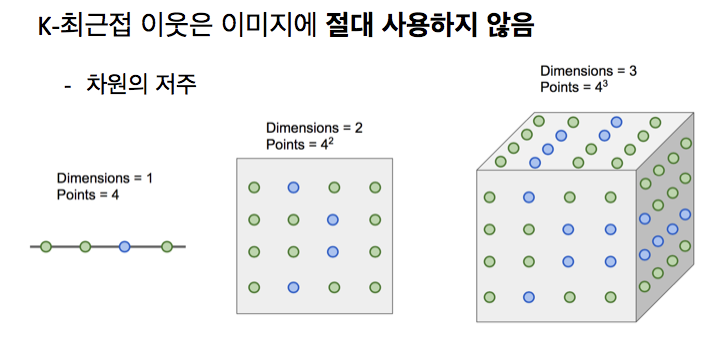
3) 차원의 저주
KNN은 학습 데이터 주변으로 페인트를 떨어뜨려 공간을 분리하는 데 사용함
Knn이 잘 동작하려면 전체 공간을 조밀하게 커버할 만큼의 충분한 트레이닝 샘플이 필요함
그렇지 않으면 최근접 이웃이 꽤 멀것이고, 테스팅 포인트와 유사하지 않을 수 있기 때문
공간을 밀도 높게 커버한다는 것은 많은 훈련 예제가 필요하다는 것인데, 문제의 차원은 지수로 증가하기에 고차원의 이미지의 경우 모든 공간을 커버할 만큼의 데이터를 모으는 일은 현실적으로 불가능함
3. Linear Classification
NN(Neural Network)과 CNN의 기반이 되는 알고리즘으로, parametric model의 기초임
NN이 레고 블럭이라면 Linear Classifier는 기본 블럭이라고 할 수 있음
딥러닝 어플리케이션에서 가장 기초적인 빌딩 블록(building block)이 선형 분류기
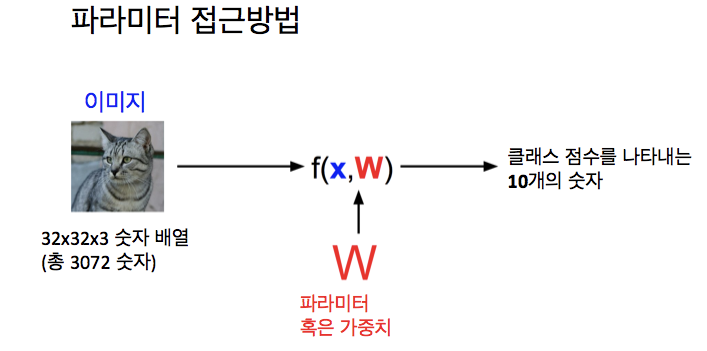
Parametric model
선형 분류기는 파라미터 모델의 가장 간단한 예임
파라미터 모델은 input으로 고양이 이미지를 받고 2개의 component(X, W)를 가짐
input data : X
parameter(or weights) : W
f : 데이터 X와, 파라미터 W를 받고 CIFAR 10에 있는 10개의 카테고리에 해당하는 점수를 나타나는 10개의 숫자를 내뱉는 함수
10개의 숫자는 데이터셋의 각 클래스에 해당하는 스코어의 개념으로, "고양이" 클래스의 스코어가 높다면 입력 X가 "고양이"일 확률이 크다라는 의
KNN : 파라미터를 이용하지 않았고, 전체 트레이닝 셋을 테스트에서 다 비교하는 방식
parametric 접근법 : train 데이터의 정보를 요약해서 파라미터 W에 모아주는 것이라 생각할 수 있음
-> 따라서 test시에 더이상 트레이닝 데이터를 직접 비교하지 않고, W만 사용할 수 있게 된 것
-> 딥러닝이란 여기서 이 함수 f를 잘 설계하는 일임
f(X, W) = WX
W와 X를 조합하는 가장 간단한 예는 둘을 곱하는 것 -> 이것이 linear classifier
먼저 입력 이미지(32x32x3)을 하나의 열벡터로 피면 (3072x1)이 됨
= 하나당 3072개 항목을 가지는 것
우리는 10개의 클래스 점수로 만들고 싶은 것이므로, 이 이미지에 대해 10개 카테고리에 대한 숫자로 만들어야 함
-> matrix W는 10 by 3072가 되어야 함
결론적으로 이 둘을 곱하면 하나의 열로 된 벡터, 즉 10 by 1의 클래스 스코어를 얻을 수 있게 됨
f(X, W) = WX + b
: bias 항을 더해준 식
bias는 데이터와 무관하게 (x와 직접 연산되지 않음) 특정 클래스에 우선권을 부여할 수 있음 = 각 클래스에 scaling offsets를 추가해줄 수 있는 것
bias는 상수 벡터로 10개의 원소로 이루어져 있고, 학습 데이터와는 상호작용하지 않고 데이터와 무관한 선호도를 제공함 = 다른 클래스보다 어떤 클래스가 더 좋다는 것을 의미하는 값이 bias
ex: 고양이가 개보다 많다면 고양이에 해당하는 bias 항목이 다른 것들보다 높을 것
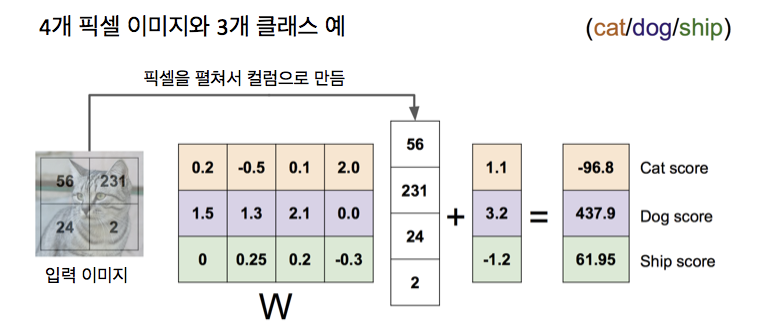
Linear Classifier의 동작 방식
input으로 2 x 2 이미지를 받아서, 4개의 항목으로 된 행 벡터 하나로 늘여 놓음
이미지 2 x 2 -> 전체 4개 픽셀
dog, cat, ship의 3개의 클래스만 사용하므로 가중치 매트릭스는 4 x 3
4개의 픽셀과 3개의 클래스기 때문
각 카테고리에 대해 데이터에 독립적인 bias 항을 줌
3개의 항목의 bias 벡터 존재
Linear classifier는 템플릿 매칭의 관점에서도 볼 수 있음
가중치 행렬 W의 각 행은 각 이미지에 대한 템플릿으로 볼 수 있고, 결국 w의 각 행과 x는 내적이 되는데, 이는 결국 클래스의 탬플릿(w)과 인풋 이미지(x)의 유사도를 측정하는것으로 이해할 수 있음
고양이 점수는 이미지 픽셀과 매트릭스의 첫번째 행의 내적 (inner product) + bias 항