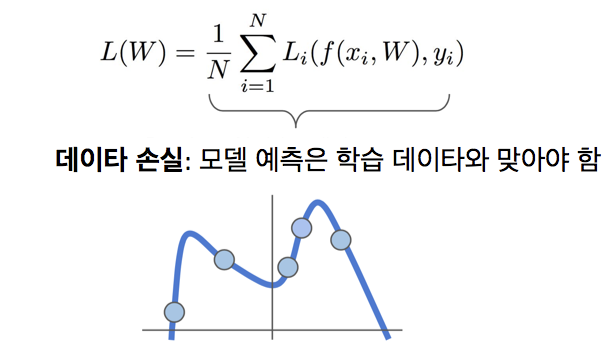
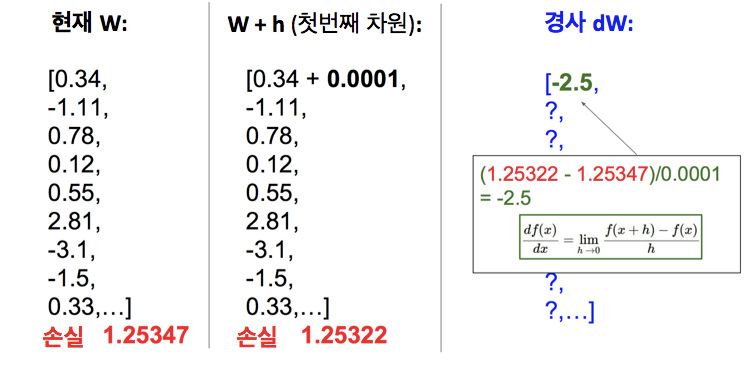
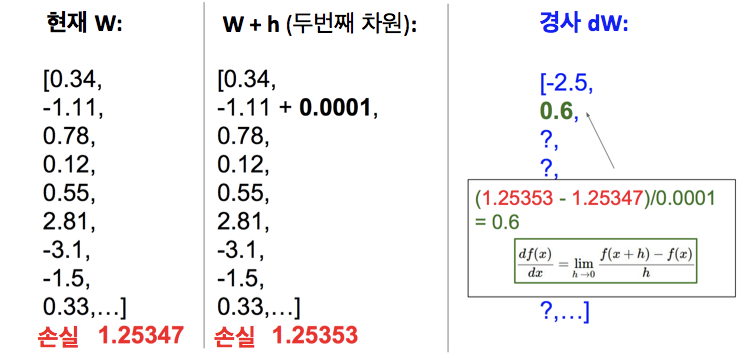
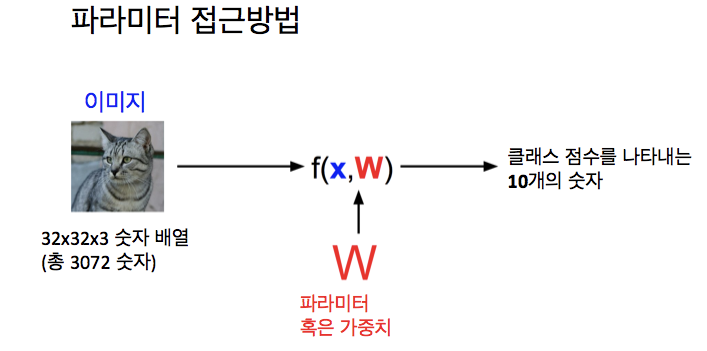
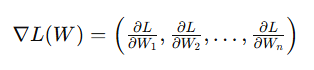- 유한 차분은 수치적(numerical)한 방법으로 경사 계산 가능 -> 추정값이지만 동시에 작성하기 쉬움
- 분석적 경사 : 일단 분석적 경사에 대한 표현을 얻으면, 이걸 유도하기 위해 모든 수학과 미분을 해야함 → 실수하기 쉬움동시에 우리의 구현을 수치적 경사로 확인해 수학을 제대로 했는지 확인하는 것
실제에서 우리가 하고 싶은 것 = 분석적 경사를 유도해서 사용하는 것
임의의 복잡한 함수에 대해 어떻게 분석적 경사를 계산하는가? = 계산 그래프(computational graph)사용! (일종의 프레임워크)
Computational graphs
앞의 강의들에서 배운 내용들을 아래와 같이 computational graphs 형태로 표현할 수 있음
computational graphs의 장점
1. input과 local gradient 값을 쉽게 파악할 수 있고, 복잡한 형태의 analytic gradient(앞 강의에서 설명한 해석적 방식)를 보다 쉽게 계산해낼 수 있음
2. 일단 계산 그래프로 함수를 표현하면 역전파(backpropagation)의 테크닉 사용 가능 -> 반복적으로 체인 룰(chain rule)을 사용해 계산 그래프의 모든 변수에 대해 gradient를 얻음

대략적인 순서는 아래와 같음
- 함수에 대한 computational graph 만들기
- 각 local gradient 구해놓기
- chain rule
- z에 대한 최종 loss L은 이미 계산되어 있음
- 최종 목표는 input에 대한 gradient를 구하는 것
Backpropagation
Chain Rule 이용해 backpropagation 가능
목표 : 함수를 가지는 것
문제 1
아래와 같이 하나의 Computation Node에 대해 국소적으로 볼 수 있음
이런 국소적 상황에서는 보다 쉽게 gradient 값을 각각 구할 수 있음
- 더하기 노드 다음의 중간 변수 : q -> q = x+y, f =qz
- x와 y에 대한 q의 경사 : 1 <- 더하기 때문
- q와 z에 대한 f의 경사 : 각각 q와 z <- 곱하기 규칙 때문
=> 목표 : x, y, z에 대한 f의 경사를 찾는 것

뒤에서부터 차례로 gradient 값 구하기 가능
마지막 값의 gradient는 1임
다음 z 값에 대한 gradient 값 = q
다음 q 값에 대한 gradient 값 = z -> 따라서 z = -4 값을 가짐

x와 y에 대한 값(df / dq)을 계산하기 위해 앞에서 계산한 gradient 값과 현재 local gradient 간에 chain rule 적용 가능함
- y에 관한 경사는 f와 직접적으로 연결되어 있지 않기 때문에 중간 노드인 q를 통해 연결하는 것
결과적으로 q 값에 대한 f의 gradient와 y값에 대한 q의 gradient를 곱하면 -4 * 1 = -4
x값 또한 -4 * 1 = -4 를 가짐을 backpropagation을 통해 유추할 수 있음
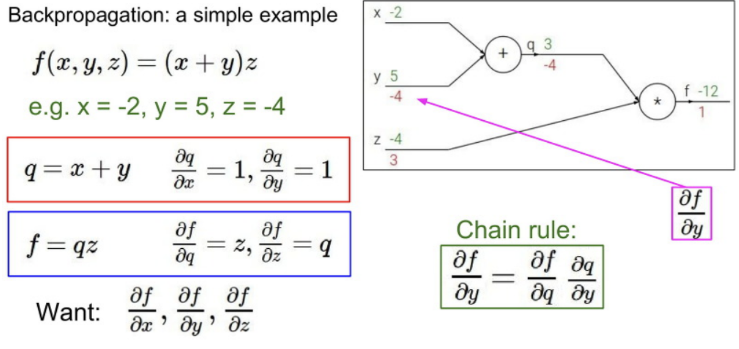
위의 설명을 더 보기 쉽게 그림으로 설명할 수 있음
x와 y값을 입력으로 받고 f라는 함수에 넣어서 z 라는 값을 얻어냄
이때 z를 x로 미분한 값과 z를 y로 미분한 값을 얻어낼 수 있는데, 이를 local gradient 값이라고 함
역전파를 할 때, 우리는 제일 뒤에서 시작함 & 끝에서 시작점으로 작업해나감
각 노드에 도달할 때 각 노드에서 직접적인 출력에 대한 거꾸로 오는 업스트림 경사(upstream gradient)를 갖게 됨
그래서 역전파에서 이 노드에 도달할 쯤에, 우리는 이미 z에 대한 우리의 최종 손실 L에 대한 경사를 계산한 것임

다음으로 찾고 싶은 것은 노드 바로 앞의 것, x와 y값에 대한 경사임 -> chain rule을 이용함
x에 대한 이 손실 함수의 경사는 (z에 대한 경사) * (이 x에 대한 z의 지역 경사)
따라서 체인 룰에서 항상내려오는 upstream gradient를 받아 지역 경사로 곱해 입력에 대한 경사를 얻음
- y에 대한 L의 경사도 같은 아이디어 적용함

즉, 각각의 노드에서 지역 경사를 얻고 역전파 중에 업스트림으로부터 오는 수치적 경사값들을 받아서 그걸 local gradient로 곱함
그리고 이 값을 연결된 노드, 즉 뒤쪽에 있는 다음 노드로 전달하는 것
이렇게 입력을 받고 loss값을 구하는 계산 과정을 forward pass라고 하고,
forward pass가 끝난 이후 역으로 미분해가며 기울기 값을 구해가는 과정은 backward pass라고 부름
몇가지 게이트 법칙은 아래와 같음
- add gate: 비율만큼 나눠줌
- max gate: 하나만 실제로 영향을 주는 값이다. 그쪽만 gradient 가짐
- 하나의 노드에서 forward로 Multi로 나가면 역전파할때 gradient 더해줘야됨
문제 2
더 복잡한 예로는 아래와 같음
빨간색 박스가 upstream gradient인데, 이 값을 이용해 지역 경사를 계산할 수 있음
df / dx = -1/x^2 인데 여기에 순방향에 사용했던 x 값인 1.37을 대입해 계산하면 -0.53이 됨

업스트림으로부터의 경사가 -0.53이고, 지역 노드는 +1
아래쪽의 c + x에 대해서는 지역 경사가 1이므로 체인 룰을 사용하면 경사는 -0.53이 됨
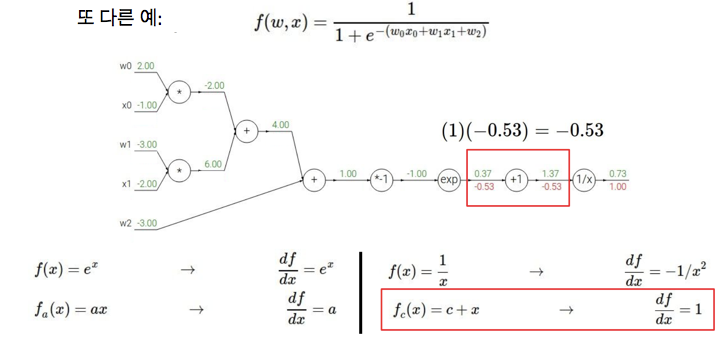
위 과정을 반복하다보면 w0과 x0에 도달하게 되고, 모든 변수에 대한 경사를 얻을 수 있게 됨
이때 x1과 w1에 대한 경사도 같은 방식으로 적을 수 있음

주의할 점은 계산 그래프를 만들 때 계산 노드를 우리가 원하는 입상(granularity)으로 정의할 수 있다는 것임
즉, 우리가 할 수 있는 만큼 완전히 간단하게 쪼갤 수 있다는 것
- 계산 그래프를 만들 때, 계산을 얼마나 세분화할지(즉, 입상을 얼마나 세밀하게 할지) 선택할 수 있음. 아주 세밀하게 나눌 수도 있고, 여러 단계들을 묶어서 하나의 큰 단계로 만들 수도 있음
아래의 파란색 박스는 sigmoid 함수와 같은 형태로, 미분 결과는 (1-sigmoid(x)) * sigmoid(x) 와 같은 형태를 가짐
시그모이드 함수를 하나의 노드로 만들어 계산 그래프에 추가해 여러 과정을 skip하고 간단하게 계산 할 수 있게 됨
아래의 예시와 같이 전체 시그모이드를 하나의 노드로 취급해서 sigmoid(x)의 출력값인 0.73를 이용하면 loss = (1-0.73) * 0.73 = 0.2 의 값을 가지는 것을 볼 수 있음
즉, 이 지역 경사 값이 0.2이므로 업스트림 경사인 1을 곱하면 정확히 시그모이드 사용 이전의 더 작은 계산으로 쪼갰을 때의 경우와 동일한 값을 얻을 수 있는 것임

계산 그래프를 세밀하게 만들면 각 단계가 단순해지지만, 그래프 자체는 복잡해지는 trade-off 관계가 존재함
- 반대로 여러 단계들을 묶으면 그래프는 간단해지지만, 각 노드에서 수행해야 하는 계산이 복잡해짐
-> 둘 사이의 균형을 맞추는 것이 중요함
경사 계산이 어렵다면 계산 그래프로 문제를 시각화하고 체인 룰을 이용해 문제를 해결할 수 있음
인풋이 벡터인 경우는 gradient가 아닌 Jacobian을 계산해주면 됨
- Jacobian matrix : 각 요소의 미분을 포함하는 행렬
- Jacobian 행렬은 야코비 행렬이라고 함. 한국에서 번역 과정에서 자코비안이나 야고비나 다양하게 불리는 것 같
또한 입력의 각 요소는 출력의 해당 요소에만 영향을 주므로 대각 행렬임

문제 3
4096 차원의 입력 벡터 (CNN을 볼 때 흔히 보는 사이즈)가 있고, 이 노드는 원소마다의(element-wise) 최대값을 취해 줌
-> 우리가 x의 f가 0과 항목마다 x를 비교해 최대값인 거고, 출력은 4096 차원의 벡터가 되는 것

이 경우의 Jacobian matrix 사이즈는 [4096 * 4096]
-> 여기서 100개의 mini batch를 가지고 있을 경우 [409600 * 409600] 사이즈를 갖게 됨
= 사이즈가 너무 거대하기에 완전히 작업하는 것이 사실상 불가능
실제에서는 대부분의 경우 이 거대한 자코비안 행렬을 계산할 필요가 없는데 그 이유를 설명하면 아래와 같음

각 요소별로 최댓값을 갖는 지점에서 어떤 일이 일어나는지를 생각해본다면 그것은 각각의 편미분한 값과 이어질 것임
입력의 어떤 차원이 출력의 어떤 차원에 영향을 주는지, 그래서 Jacobian 행렬은 대각선 형태의 구조를 볼 수 있음
입력의 각 요소는 오직 출력의 해당 요소에만 영향을 주기 때문에 Jacobian 행렬은 대각 행렬이 될 것임
-> 실제로 공식화할 필요 없이 채워넣어서 사용하기만 하면 됨
문제 4

알고 싶은 것 : q에 대한 경사
q는 L2앞의 중간 변수로, 2차원 벡터
=> 목표 : q의 각 원소가 어떻게 f의 최종 값에 영향을 주는지 알아내는 것
ex : q1에 대한 f의 경사는 f(q) 미분하면 2q1이 됨 -> qi의 각 원소에 대한 표현을 벡터 형태로 쓰면 2*q로 놓을 수 있음

w에 대한 경사를 얻어 각 원소별로 계산할 수 있고, 이를 벡터화된 형식으로 적을 수 있음
이때 변수에 대한 경사를 항상 체크해야 하는데, 변수와 같은 형태를 가져야 함
- 경사의 각 원소는 그 원소가 최종 출력에 얼마나 영향을 미치는 지 정량화한 것이기 때문

위를 벡터화된 형태로 적으면 아래와 같음

벡터의 gradient는 항상 원본 벡터의 사이즈와 같아야 함을 주의
위 과정들을 모듈화하면 아래와 같음

계산 그래프에서 노드에서 지역 경사 계산 -> 내려오는 업스트림 경사를 그것들과 연결
이 과정을 forward와 backward의 API로 생각할 수 있음
forward에서 이 노드의 출력을 계산하는 함수를 구현하고, backward에서 경사를 계산함
아래는 특정 게이트에 대한 구현임
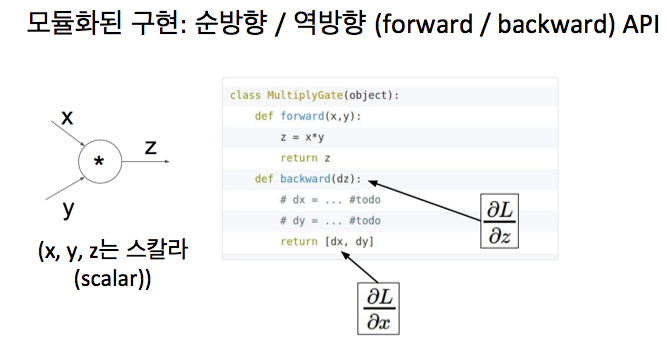
- forward : x와 y를 입력으로 받아 z값 반환함
- backward : dz를 입력으로 받음 (업스트림 경사) & 아래로 내려가는 x와 y에 대한 경사인 dx, dy 출력
아래는 모든 것이 scalar인 경우

순방향으로 보면 -> forward의 모든 값을 저장하고 있어야 함. 많은 경우 backward가 이걸 사용하기 때문
forward에서 x, y를 저장하고, backward에서 체인 룰을 사용해서 업스트림 경사의 값을 취하고 다른 가지의 값을 곱함
그래서 dx에 대해 저장했던 self.y의 값을 dz로 곱함 (dy에 대해서도 같음)
많은 딥러닝 프레임워크와 라이브러리에서 이런 모듈화를 따르고 있음 ex) Caffe

Neural Networks
: 신경망은 함수들의 집합(class)로 비선형의 복잡한 함수를 만들기 위해 간단한 함수들을 계층적으로 여러 개 쌓아올리는 형태임
이전까지는 linear score function (ex : f = Wx)를 최적화하고자 하는 함수의 예로 사용했음
이제는 이 선형 함수 대신 변형으로 2개의 layer로 된 신경망을 얻을 수 있음
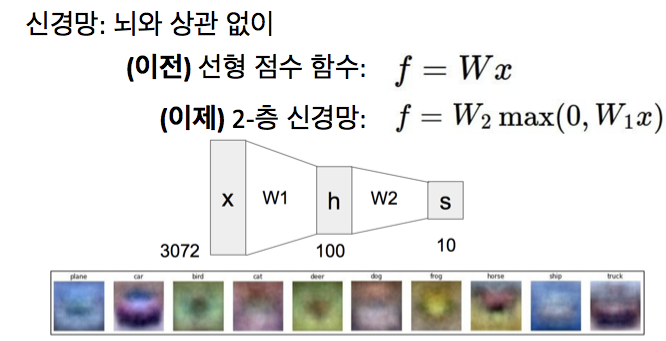
위 식은 W1과 x를 행렬 곱셈해서 중간값을 얻고 0과 W의 최대값(max of 0 and W)을 취하는 비선형 함수를 가짐
= 이 선형 layer과 출력과의 최대값
이 형태는 비선형성을 가진다는 것이 중요함
비선형성이 없으면 선형 레이어를 다른 레이어 위에 쌓으면 하나의 선형 함수가 될 뿐이기 때문임
그래서 행렬 곱과 선형 레이어를 취해서 여러 개를 쌓는데, 그 사이에 비선형 함수를 넣는 것임
그 후 score function을 얻고 score의 출력 벡터를 얻을 수 있음
linear score function는 가중치 행렬 W와 입력 데이터의 내적을 계산해 각 클래스에 대한 점수를 산출함
이 때 W의 각 행을 특정 클래스에 대한 템플릿으로 생각할 수 있는데, 입력 이미지가 주어졌을 때 신경망은 해당 입력이 이 템플릿과 얼마나 유사한지 계산해 "자동차" 클래스에 대한 점수를 산출함
이때 단일 템플릿만을 사용하면 다양한 스타일의 자동차를 인식하기 어렵다는 단점이 생김
- ex: 빨간 자동차의 템플릿이 있다면 빨간 자동차는 잘 인식하지만 노란 자동차나 다른 스타일의 자동차는 인식하지 못할 수 있음
=> 현실에서는 여러 스타일과 색상의 자동차가 존재하기 때문에 단일 템플릿만으로는 충분하지 않음
-> 다층 신경망에서는 여러 layer의 가중치 행렬을 사용해 이러한 문제를 해결함
다층 신경망
예를 들어, 첫 번째 가중치 행렬 W1은 여전히 여러 템플릿을 포함할 수 있으며, 각 템플릿은 특정한 자동차 스타일(빨간 차, 노란 차 등)을 나타낼 수 있음
그런 다음, hidden layer h에서 이러한 템플릿들에 대한 점수들을 계산한 후, 두 번째 가중치 행렬 W2를 사용하여 이 점수들을 결합하고 조합할 수 있음
-> 다양한 스타일의 자동차를 모두 포함하는 템플릿을 학습할 수 있게 되는 것
-> 따라서, 신경망은 빨간 차뿐만 아니라, 노란 차와 다른 색상의 자동차도 잘 인식할 수 있음

실제 뉴런과 인공신경망
강의에서는 인공신경망이 인간의 실제 뉴런과 유사하다고 이야기하는 것을 경계하고 있음
실제로 생물학적 뉴런은 종류도 다양하고 훨씬 더 복잡한 연산을 수행하기 때문임

Activation Function
이 중 현재 가장 많이 사용하는 활성화 함수는 ReLU임

Neural Networks : Architectures
아래의 왼쪽 그림을 2-layer Neural Net 또는 1-hidden-layer Neural Net이라고 함
기본적으로 weight를 갖고 있는 것만 layer라고 하기 때문에 3-layer가 아니라 2-layer
그래서 input layer는 weight를 가지고 있지 않기 때문에 제외가 됨
- 오른쪽의 경우도 3-layer neural network 또는 2-hidden-layer Neural Network라고 부름
모든 노드들이 연결되어 있는데, 이런 경우를 Fully-connected layer라고 부르며 줄여서 FC layer라고 함

Example : feed-forward computation of a Neural Network
layer로 구성하는 이유 = 효율적으로 계산을 할 수 있기 때문
- 행렬 벡터 연산을 사용해 신경망을 구성하여 이 부분에서 효율적이라 함

위 그림에서 3-layer neural network를 떠올려보면 입력: [3x1] vector
첫 번째 hidden layer의 가중치 [4x3]의 크기 & 모든 노드에 대한 bias는 [4x1] vector에 있음
모든 단일 뉴런에서는 가중치 가 있으므로 행렬 벡터 곱셈 np.dot(W1,x)는 모든 layer에 있는 뉴런의 활성화를 계산함
hidden layer의 는 [4x4] 행렬을, 마지막 output layer에 대한 은 [1x4] 행렬이 됨
=> 이 3-layer 신경망의 forward pass는 activation function과 섞인 3개의 행렬 곱셈이라 볼 수 있음
- 하나의 layer는 하나의 연산을 통해 계산해 편의성을 제공
[CS231n 4강 정리] 역전파(Back propagation), 신경망(Neural Network) (tistory.com)
[CS231n 4강 정리] 역전파(Back propagation), 신경망(Neural Network)
지난시간까지 w와 스코어, loss function, 그리고 gradient를 배웠습니다. 오늘은 이제 실제로 analytic gradient(앞 강의에서 설명한 해석적 방식) 를 어떻게 계산하는지에 대해서 알아봅시다. 역전파(Back Pr
oculus.tistory.com
cs231n 4강 정리 - Introduction to Neural Networks (velog.io)
cs231n 4강 정리 - Introduction to Neural Networks
이번 포스팅은 standford university의 cs231 lecture 4를 공부하고, 강의와 슬라이드를 바탕으로 정리한 글임을 밝힙니다.제가 직접 필기한 이미지 자료는 별도의 허락 없이 복사해서 다른 곳에 게시하는
velog.io
'AI > CS231N Review' 카테고리의 다른 글
| [CS231N] Lecture 3 - Loss Functions and Optimization (5) | 2024.07.23 |
|---|---|
| [CS231N] Lecture 2 - Image Classification (0) | 2024.07.16 |
| [CS231N] Lecture 1 - Introduction to Convolutional Neural Networks for Visual Recognition (2) | 2024.07.15 |