
[논문 리뷰] ControlNet : Adding Conditional Control to Text-to-Image Diffusion Models
paper : https://arxiv.org/pdf/2302.05543.pdf
ControlNet은 pretrained text-to-image diffusion model에 대한 extra conditions를 추가함으로써 이미지 생성을 컨트롤하는 neural network이다. prompt 대신 input conditioning images의 sematics (ex_ edges, poses, depth 등)을 직접 인식하는 것이다. ControlNet을 사용해 다음과 같은 작업을 수행할 수 있다.
- Specify human poses
- Copy the composition from another image
- Generate a similar image
- Turn a scribble into a professional image
ControlNet을 간략하게 설명하자면, large image diffusion model의 weights를 trainable copy와 locked copy로 복제한 다음 trainable copy를 input condition에 대해 훈련시키는 것이다. 이 두 block은 zero convolution으로 연결된다.
Abstract
본 연구에서 소개하는 ControlNet은 pretrained된 대규모 text-to-image diffusion model에 공간적인 conditioning을 추가하는 신경망 아키텍처이다. ControlNet은 대규모 diffusion model을 잠그고(lock), 수십억 개의 이미지로 pretrained된 깊고 강력한 인코딩 레이어를 백본으로 재사용해 다양한 조건부 제어 세트를 학습한다.
neural architecture는 0에서 점진적으로 파라미터를 증가시키는 "zero convolutions" (zero-initialized convolution layers)로 연결되어 있어서 유해한 노이즈가 finetuning에 영향을 미치지 않도록 한다. 또한 edges, depth, segmentation, human pose 등 다양한 conditioning controls를 단일 또는 여러 조건을 사용해 프롬프트 유무에 관계없이 SD로 테스트한다. 또한 소규모(50k미만) 및 대규모(1m 이상) dataset에서도 robust함을 보인다.
Introduction
text-to-image model은 이미지 공간을 제어하는 데 한계가 존재했고,텍스트 프롬프트만으로는 복잡한 레이아웃, 포즈, 모양, 형태를 정확하게 표현하기가 어려웠다. 머릿속의 이미지와 정확히 일치하는 이미지를 생성하기 위해 프롬프트를 편집하고 결과 이미지를 검사한 다음 프롬프트를 다시 편집하는 수많은 시행착오를 반복해야 하는 경우가 많았다.
머신러닝과 컴퓨터 비전에서는 사용자가 원하는 이미지 구성을 직접 지정할 수 있도록 추가 이미지(예: edge maps, human pose skeletons, segmentation maps, depth, normals 등)를 이미지 생성 프로세스의 condition으로 처리하는 경우가 많다. image-to-image model은 컨디셔닝 이미지에서 목표 이미지로 매핑을 학습한다.
이미지 변형 생성, inpainting과 같은 몇 가지 문제는 학습이 필요없는 기술(training free techniques)로 해결할 수 있지만, depth-to-image, pose-to-image 등과 같은 더 다양한 문제에는 end-to-end 학습과 데이터 기반의 솔루션이 필요하다.
- 학습이 필요없는 기술의 예 : denoising diffusion process, editing attention layer activations
하지만 대규모 text-to-image diffusion model에서 conditional controls를 end-to-end 방식하는 것은 쉽지 않다. 특정 조건에 대한 학습 데이터의 양이 일반적인 text-to-image 학습에 사용할 수 있는 데이터보다 훨씬 적을 수 있기 때문이다. 제한된 데이터로 pretrained된 대규모 모델을 직접 finetuning하거나 계속 훈련하면 과적합 및 catastrophic forgetting이 발생할 수 있다.
- catastrophic forgetting(파괴적 망) : 새로운 데이터에 학습을 지속할 때 이전에 학습한 정보를 심각하게 잊어버리는 것
이러한 문제는 훈련 가능한 파라미터의 수나 순위를 제한함으로써 완화할 수 있으나, 본 연구에서는 복잡한 shape과 다양한 high-level semantics를 가진 conditioning image를 처리하기 위해 더 심층적이거나 맞춤화된 신경 아키텍처를 설계하였다.
논문에서 제안하는 ControlNet은 pretrained text-to-image diffusion model(본 논문의 inplementation에는 SD)을 위한 conditional controls를 학습하는 end-to-end neural network architecture이다.
- end-to-end : 시스템의 모든 구성 요소를 통합해 전체 프로세스를 한 번에 처리하는 방식. 입력 데이터가 시스템에 입력되면 출력 결과가 나올 때까지 모든 중간 단계를 포함해 완전한 처리를 수행함. 개별적으로 최적화된 서브시스템을 별도로 통합하는 것이 아니라, 전체 시스템이 한 번에 최적화되도록 설계됨. 입력부터 출력까지 '파이프라인 네트워크'가 없이 한 번에 처리한다는 뜻.
- 파이프라인 네트워크 : 전체 네트워크를 이루는 부분적인 네트워크
ControlNet은 두 개의 neural network block을 가진다. 본 논문에서는 그 중 하나를 locked copy라고 부르고, 또다른 하나를 trainable copy라고 부른다. 이 둘은 original model의 weigts들의 copy들로, locked copy는 파라미터를 frozen시켜 훈련에 사용하지 않고, trainable copy만 훈련에 사용한다. 파라미터를 lock(frozen)하고 trainable copy를 만들어서 대규모 모델의 품질과 성능을 보존하는 것이다. 이 아키텍처는 pretrained 대규모 모델을 다양한 조건부 학습을 위한 강력한 백본으로 취급한다. 그리고 이 두 neural net block은 특별한 종류의 convolution layer인 zero convolution layers로 연결되어 훈련동안 0에서 점진적으로 증가한다.
- 0으로 initialize하는 이유? : noise된 conv layer라면 condition을 받고 trainable copy로 전달해줄 때 초반 몇 step 만에 trainable copy가 condition을 잘 이해하지 못하고 망가질 가능성이 높기 때문
이 아키텍처는 훈련 초기에 대규모 diffusion modeld의 deep features에 유해한 노이즈가 추가되지 않도록 하며, trainable copy의 대규모 pretrained 백본이 이러한 노이즈로 인해 손상되지 않도록 보호한다. zero convolution이 새로운 노이즈를 더하지 않기 때문에 학습 역시 diffusion model의 finetuning만큼 빠르다.
- zero convolution layer : weight, bias가 모두 0으로 initialize된 layer
위 논문에서 ControlNet이 다양한 conditioning inputs(예: Canny edges, Hough lines, user scribbles, human key points 등)으로 SD를 제어할 수 있음을 확인했다. 텍스트 프롬프트가 있든 없든 단일 conditioning image를 사용해 테스트했고, multiple conditions을 어떻게 서포트하는지 입증한다. 또한 다양한 크기의 데이터 세트에서 ControlNet의 훈련이 강력하고 확장 가능하며, depth-to-image conditioning과 같은 일부 작업의 경우 단일 NVIDIA RTX 3090Ti GPU에서 컨트롤넷을 훈련하면 대규모 컴퓨팅 클러스터에서 훈련된 산업용 모델과 경쟁할 수 있는 결과를 얻을 수 있음을 보였다.
- depth-to-image conditioning : 컴퓨터 비전과 관련된 기술로서, 특정 깊이 데이터를 기반으로 이미지 생성 프로세스를 조건화하는 과정. 주어진 깊이 정보에 따라 이미지를 생성하도록 모델을 학습시키는데 이용됨.
따라서 본 논문을 요약하면,
1. 효율적인 finetuning을 통해 pretrained text-to-image diffusion model에 공간적으로 국소화된 input conditions를 추가할 수 있는 신경망 아키텍처인 ControlNet을 제안
2. Canny edges, Hough lines, user scribbles, human key points, segmentation maps, shape normals, depths, cartoon line drawings를 조건으로 SD를 제어하는 pretrained ControlNet을 제시
3. 여러 대안 아키텍처와 비교한 실험을 통한 검증 & 다양한 작업에 걸쳐 이전의 여러 기준에 초점을 맞춘 user studies
의 내용이 담겨있다 .
Related Work
Finetuning Neural Networks
neural network를 finetuning하는 방법은 학습 데이터를 추가해 직접 학습을 계속하는 것이다. 하지만 이 방식은 과적합, mode collapse, catastrophoc forgetting으로 이어질 수 있어서 이러한 문제를 막기 위한 finetuning 전략 개발이 광범위하게 진행되어왔다.
- HyperNetwork : NLP 커뮤니티에서 시작된 접근 방식으로, 작은 순환 신경망을 훈련해 더 큰 신경망의 가중치에 영향을 미치는 것을 목표로 함.
- Adapter : pretrained transformer model에 새로운 모듈 레이어를 삽입해 다른 작업에 맞게 사용자 정의하기 위해 NLP에서 널리 사용됨. 사전 학습된 백본 모델을 다른 작업으로 전송하기 위해 CLIP과 함께 자주 사용됨. 연구에서 사용되는 T2IAdapter는 외부 조건에 따라 SD를 조정함.
- Additive Learning : 원래 모델의 가중치를 frozen하고 학습된 weight masks, pruning(가지치기), hard attention을 사용해 소수의 새로운 파라미터를 추가함으로써 망각을 방지함.
- LoRA : 매개변수화된 많은 모델들이 low intrinsic dimension subspace에 존재한다는 결과에 기반해 lowrank 행렬로 매개변수의 오프셋을 학습함으로써 catastrophic forgetting을 방지함.
- zero-initialized layers : ControlNet에서 네트워크 블록들을 연결하는 데에 사용됨.
Image Diffusion
- Image Diffusion Models : LDM은 latent image space에서 수행해 계산 비용을 절감함. text-to-image diffusion models은 CLIP과 같은 pretrained 언어 모델을 통해 텍스트 입력을 latent vector로 인코딩함. Glide는 이미지 생성 및 편집을 지원하는 텍스트 유도 확산 모델임. Disco diffusion은 clip guidance와 함꼐 텍스트 프롬프트를 처리함. Stable Diffusion은 latent diffusion을 대규모로 구현한 것임. Imagen은 latent image를 사용하지 않고 피라미드 구조를 사용해 픽셀을 직접 확산함.
- Controlling Image Diffusion Models : image diffusion process는 색상변화 및 인페인팅에 대한 일부 제어 기능을 직접 제공함. Text-guided control methods 방법도 존재함. MakeAScene은 세그멘테이션 마스크를 토큰으로 인코딩해 이미지 생성을 제어함. SpaText는 분할 마스크를 localized token embedding으로 매핑함. GLIGEN은 diffusion model의 attention layer에서 새로운 매개변수를 학습함. Textual Inversion과 DreamBooth는 image diffusion model을 finetuning함으로써 생성된 이미지의 콘텐츠를 개인화할 수 있음. Promptbased image editing은 프롬프트를 사용해 이미지를 조작할 수 있는 실용적인 도구를 제공함.
Image-to-Image Translation
Contidional GANs와 transformer는 서로 다른 이미지 도메인 간의 매핑을 학습할 수 있음.
Method
ControlNet은 공간적으로 국소화된 task-specific image conditions으로 pretrained text-to-image diffusion models을 향상시킬 수 있는 신경망 아키텍처다.
ControlNet
ControlNet은 신경망의 블록에 추가적인 conditions을 주입한다.

(a) : neural network block : feature map x를 입력으로 받아 다른 feature map y를 출력
(b) : (a)에 ControlNet 추가한 bolck. neural network block을 locked한 것인 locked copy와 trainable copy를 만든 다음 zero convolution layer(가중치와 바이어스가 모두 0으로 초기화된 1× 1 convolution)을 사용해 서로 연결한다.
- ControlNet은 large diffusion model의 weights를 trainable copy와 locked copy로 복제함
- trainable copy : conditional control을 배우기 위해 task-specific 데이터셋에 대해 학습된 것
- locked copy : 기존 network의 capability를 보존함
output y_c의 c는 네트워크에 추가하고자 하는 conditioning vector이다.
(a)를 diffusion process에 접목시키게 되면 특정 시점의 noised latent vector z_t가 input으로 들어가서 다음 시점의 noised latent vector z_(t-1)을 예측하는 것과 같다.
(b)의 locked neural network block은 원래의 diffusion model로 파라미터가 고정된채 변하지 않게끔 하면 하면 사전 학습된 디퓨전 모델의 이미지를 만드는 성능을 해치지 않고 가만히 놔둘 수 있다. 회색의 locked는 가만히 놔두고 우측의 trainable copy만 condition에 대해 학습하는 것이다.
구체적으로 어떻게 해당 학습이 효과적으로 conditioning을 할 수 있는지 수식적으로 살펴볼 수 있다.
(a) neural network block
2D feature에서 feature map x가 정의되어 있다면, neural network block F(; Θ)는 블록에 포함되는 파라미터 Θ를 통해 input feature map x를 y로 transform하게 된다.
- network block : 신경망의 단일 unit을 형성하기 위해 조합되는 neural layer들(ex: "resnet" block, "conv-bn-relu" block, multi-head attention block, transformer block 등)을 지칭함

- F(; Θ) : 파라미터 Θ를 사용해 feature map x를 다른 feature map y로 변환하는 훈련된 neural block - Figure 2. (a)
- Θ : 파라미터들의 집합
- feature map x : R {h, w, c} height, width, number of channels in the map
(b) (a) + ControlNet
pretrained neural block에 ControlNet을 추가하려면, 원본 block의 파라미터 Θ를 lock하고(학습하지 않을 것) 이를 복사한 파라미터 Θ_c를 사용해 trainable copy에 블록을 복제한다. (Θ_c는 Θ를 똑같이 복제한 것)
- trainable copy parameter Θ_c 는 external conditioning vector(input condition) c를 input으로 받아 학습에 사용
이 구조를 SD와 같은 대규모 모델에 적용하면 locked parameters는 수십억 개의 이미지로 훈련된 production-ready model을 보존하고, trainable copy는 이러한 large pretrained models을 재사용해 다양한 input conditions를 처리하기 위한 깊고 견고한 백본을 구축한다.
Zero convolution
훈련 가능한 copy를 Z라 할 때, 이 Z는 zero convolution layers로 locked model에 연결된다. 구체적으로 Z는 가중치와 바이어스가 모두 0으로 초기화된 1×1 convolution layer이다. 각 neural block의 앞 뒤로 하나씩 붙는다고 생각하면 된다.
- zero convolution은 feature map의 크기를 변화시키면 안되기 때문에 1×1 크기를 가지는 convolution이고, weight와 bias모두 0으로 초기화된 상태로 학습이 시작된다. input에 상관없이 처음엔 모두 0으로 output을 내뱉는다.
ControlNet을 구축하기 위해 각각 파라미터 Θ_z1, Θ_z2를 갖는 두 개의 zero convolutions 객체를 사용한다. 그러면 완전한 ControlNet은 ControlNet block의 output인 y_c를 계산한다.


즉 위 식에서 +로 붙은 부분이 ControlNet에 해당하는 부분이고, 그 앞의 F(x; Θ)가 (a)에 해당하는 부분인 것이다.
첫 번째 훈련 단계에서는 zero convolution layer의 가중치와 바이어스 파라미터가 모두 0으로 초기화되므로 위 식의 Z 항이 모두 0으로 평가된다. 따라서 아래와 같은 식을 얻을 수 있다.

첫 번째 식이 y, 마지막 줄이 y_c를 의미한다. 위 식은 다음과 같이 해석된다.

이 내용이 암시하는 것은, training이 시작되는 당시에는 ControlNet 구조에 의한 input/output 관계가 사전학습된 diffusion의 input/output과 전혀 차이가 없다는 것이다. 쉽게 말해 ControlNet이 기존 neural network block에 적용되더라도 optimization되기 전에는 neural network 깊이가 증가해도 영향을 미치지 않는다는 것이다.
이렇게 하면 훈련이 시작될 때 유해한 노이즈가 훈련 가능한 copy Z의 신경망 레이어의 hidden states에 영향을 줄 수 없다. 또한, Z(c; Θ_z1) = 0 이고, Z도 input 이미지 x를 받으므로 Z는 완전히 작동하며 pretrained model의 기능을 유지해 추가 학습을 위한 강력한 백본 역할을 할 수 있다. 기존 모델 neural block의 capability, functionality, result quality는 완벽히 보존되며, 이후의 optimization 과정은 finetuning만큼 빠르다. (scratch부터 해당 layer들을 학습시키는 것보다 훨씬 빠르다. )
zero convolutions는 초기 훈련 단계에서 random noise를 gradients로 제거하여 이 백본을 보호한다. 근데 weight, bias를 0으로 주면 학습이 안되는거 아니냐라는 질문을 할 수 있는데, 이는 아래의 간단한 미분식으로 아니라는 것이 증명된다.

즉 w=0이고 input x는 0이 아닐 때 편미분 값이 0이 아니므로 backpropagation을 통해 0이 아닌 값으로 업데이트가 되는 것이다.
좀 더 일반화해서 설명을 하면
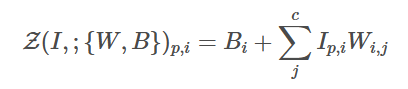
zero convolution의 forward process가 위와 같을 때 (W = weight, B= bias) gradient는 아래와 같다.


0이 아닌 weight를 만들기 때문에 다음 step에서는 0이 아닌 어떠한 다른 값으로 update가 된다.

ControlNet for Text-to-Image Diffusion
> SD를 예로 ControlNet이 어떻게 pretrained diffusion model에 조건부 제어를 추가할 수 있는가?
ControlNet 부분은 Stable diffusion encoder block을 그대로 복사하여 encoder 부분만 학습을 시켜서 condition이 포함된 encoding을 하는 것이다.
(a) Stable Diffusion
- 기본적으로 인코더, 디코더, 중간 block, skip-connected decoder가 있는 U-Net 구조
- 인코더와 디코더는 모두 12개의 블록을 포함하며, 전체 모델에는 중간 블록을 포함해 25개의 블록이 포함됨
- 25개 블록 중 8개 블록은 다운샘플링 또는 업샘플링 컨볼루션 레이어
- 나머지 17개 블록은 각각 4개의 리셋 레이어와 2개의 ViT를 포함하는 메인 블록임
- 각 ViT에는 여러 개의 cross-attention self-attention mechanism이 포함됨

- 위 그림에서 (a)는 4개의 리셋 레이어와 2개의 ViT가 포함되어 있으며, “×3” 은 이 블록이 세 번 반복됨을 나타낸다.
- 잠긴 회색 블록 : SD V1.5(또는 동일한 U-Net 아키텍처를 사용하는 V2.1)의 구조 보여줌
- 훈련 가능한 파란색 블록과 흰색 제로 컨볼루션 레이어가 추가되어 ControlNet을 구축함
- text prompt : CLIP text encoder 사용해 인코딩함
- diffusion timesteps : positional encoding을 사용하는 time encoder 사용해 인코딩함
(a)와 같이 사전 훈련된 diffusion model(ex: SD의 latent UNet)의 파라미터(가중치)를 복제해 "trainable copy"와 "locked copy"로 나눈다. locked copy는 대규모 데이터셋에서 학습한 방대한 지식을 보존하고, trainable copy는 과제별 측면을 학습하는 데 사용된다. trainable copy와 locked copy의 매개변수는 zero convolution layer로 연결된다.
ControlNet 구조는 UNet의 각 encoder level에 적용된다. 특히 12개의 인코딩 블록과 1개의 SD 중간 블록의 훈련 가능한 copy를 생성하는 데 ControlNet을 사용한다. 12개의 인코딩 블록은 4개의 해상도(64×64, 32×32, 16×16, 8×8)로 구성되며, 각 블록은 3번씩 복제된다.
output은 12개의 skip-connections과 1개의 중간 블록에 추가된다. SD는 UNet 구조이므로 이 제어망 아키텍처는 다른 모델에도 적용될 수 있다. locked copy parameters가 frozen되어있기 때문에 finetuning을 위한 원래의 locked encoder 기울기 계산이 필요하지 않으므로 계산적으로 효율적이다. (GPU 메모리 절약에 좋은 방식임)
- skip-connections : 딥러닝에서 사용되는 네트워크 구조 중 하나로, 입력 데이터가 네트워크의 여러 layer를 건너뛰어 출력 layer에 직접 연결되는 방식을 의미. 그래디언트 소실 문제를 완화하는 데 사용됨 ex) ResNet, UNet
- UNet에서는 skip-connection을 통해 downsampling 과정에서 발생하는 정보의 손실을 보충함. UNet은 구조상 하이레벨 feature를 뽑는 과정에서 feature에 대한 정보는 얻지만, 정확한 detail적인 측면에서는 손실이 발생함. 이런 문제를 Upsampling 이후 skip connection을 만들어서 detail을 보충하는 방식으로 해결함

좌 : 평범한 블록 / 우: skip-connection을 이용한 블록 - 위에서 보면 알 수 있듯 일반 블록과 다르게 2개의 conv layer를 뛰어넘어버리는 것을 볼 수 있다.
- UNet에서는 skip-connection을 통해 downsampling 과정에서 발생하는 정보의 손실을 보충함. UNet은 구조상 하이레벨 feature를 뽑는 과정에서 feature에 대한 정보는 얻지만, 정확한 detail적인 측면에서는 손실이 발생함. 이런 문제를 Upsampling 이후 skip connection을 만들어서 detail을 보충하는 방식으로 해결함
Image Diffusion models: 점진적으로 이미지 노이즈를 제거 & 훈련 도메인에서 샘플 생성하는 방법 학습함
노이즈 제거 과정은 pixel 공간 또는 훈련 데이터에서 인코딩된 잠재 공간에서 발생할 수 있음
SD는 잠재 이미지를 훈련 도메인으로 사용함 & VQ-GAN과 유사한 전처리 방법을 사용해 이미지를 더 작은 잠재 이미지로 변환함
SD는 학습 과정의 안정화를 위해 512 × 512 이미지로 이루어진 전체 dataset을 64 × 64 latent images로 변환하는 pre-processing method를 사용한다. (VQ-GAN과 유사)
이는 ControlNet 역시 convolution size를 맞추기 위해 image based condition을 64 × 64 feature space로 보내야 함을 의미한다. 논문에서는 tiny network ε()를 사용해 encode 한다.
따라서 SD에서 ControlNet을 추가하는 과정을 정리하면 아래와 같다.
1. 각 input conditioning image(ex: edge, pose, depth 등)를 512 × 512의 크기에서 SD의 크기와 일치하는 64 × 64 feature space vector로 변환함
2. 4 × 4 kernels과 2 × 2 strides로 구성된 4개의 convolution layer로 구성된 tiny network ε()를 사용해 image space condition ci를 feature space conditioning vector c_f로 encode함
encoder는 512 × 512 condition을 64 × 64 feature map으로 만든다.
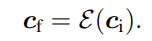
latent diffusion process는 conditioning part와 실제디퓨전 모델 학습이 end-to-end가 아닌 분리된 형태를 가진다는 특징이 존재했다. 따라서 end-to-end 학습을 할 수 있는 방법을 강구하게 되었고, 그 방법으로 ControlNet이 제안된 것이다.
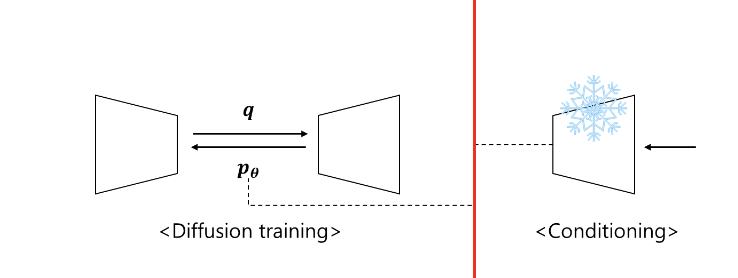
앞의 내용들을 간단하게 요약하면 아래와 같다.
- diffusion model의 parameter를 복사해 새로운 학습 프레임워크를 원래 parameter와 병렬로 구성
- 이를 trainable(학습가능한) copy와 locked(학습 불가능한) copy라 칭함
- locked copy는 기존 network의 성능인 이미지 생성에 필요한 representation을 유지하고 있음
- trainable copy는 conditional control을 위해 여러 task-specific dataset에 대해 학습되는 프레임워크임
- locked copy와 trainable copy는 zero convolution을 통해 서로 연결됨
- zero convolution 또한 학습 가능한 레이어에 속한다.
Training
입력 이미지 z_0이 주어지면 image diffusion 알고리즘은 이미지에 노이즈를 점진적으로 추가해 노이즈가 있는 이미지 z_t를 생성하고, t는 노이즈가 추가된 횟수를 나타낸다. time step t, text prompt c_t, task-specific condition c_f를 포함한 conditions들이 주어지면 image diffusion 알고리즘은 아래의 loss를 이용해서 네트워크 ϵ_θ를 학습해 노이즈 이미지 z_t에 추가된 노이즈를 예측한다.
- loss는 기존 diffusion 알고리즘에 task specific condition c_f만 추가한 형태임

위의 learning objective는 ControlNet으로 diffusion model을 finetuning하는 데 직접 사용된다.
훈련 과정에서 text prompt c_t의 50%는 빈 문자열로 무작위로 대체된다. 훈련 과정에서 zero convolution은 네트워크에 노이즈를 추가하지 않기 때문에 모델은 항상 고품질 이미지를 예측할 수 있어야 한다.
Experiments



- Prompt: Professional high-quality wide-angle digital art of a house designed by frank lloyd wright. A delightful winter scene. photorealistic, epic fantasy, dramatic lighting, cinematic, extremely high detail, cinematic lighting, trending on artstation, cgsociety, realistic rendering of Unreal Engine 5, 8k, 4k, HQ, wallpaper
- Negative Prompt: longbody, lowres, bad anatomy, bad hands, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality
자세히 프롬프트를 줬을 때 ControlNet을 쓰지 않고 SD만으로도 퀄리티있는 이미지가 생성됨을 알 수 있다. 하지만 ControlNet을 사용함으로 이미지의 레이아웃이 잡힌 채로 생성이 되는 것을 볼 수 있다.

Skip connection과 LSTM에 대하여 : 네이버 블로그 (naver.com)
Skip connection과 LSTM에 대하여
skip connection(=residual architecture)를 이용하면 layer가 깊어져도 안정적으로 gradient를 업데...
blog.naver.com
ControlNet: A Complete Guide - Stable Diffusion Art (stable-diffusion-art.com)
ControlNet: A Complete Guide - Stable Diffusion Art
ControlNet is a neural network that controls image generation in Stable Diffusion by adding extra conditions. Details can be found in the article Adding
stable-diffusion-art.com
Welcome to JunYoung's blog | ControlNet 논문 이해하기 및 사용해보기 (junia3.github.io)
Welcome to JunYoung's blog | ControlNet 논문 이해하기 및 사용해보기
들어가며 ControlNet의 논문 제목 풀네임은 ‘Adding conditional control to text-to-image diffusion models’이다. 이른바 ControlNet이라고 불리는 이번 연구는 사전 학습된 large diffusion model을 어떻게 하면 input condit
junia3.github.io
[논문리뷰] ControlNet: Adding Conditional Control to Text-to-Image Diffusion Models
depth, canny, segmentation 등으로 pretrained diffusion model을 컨트롤 하는 ControlNet을 알아보자
jang-inspiration.com
+) 이건 앞에서 리뷰했던 IPAdapter과 ControlNet의 차이점
Difference/use case between ipadapter and control net? : r/StableDiffusion (reddit.com)
From the StableDiffusion community on Reddit
Explore this post and more from the StableDiffusion community
www.reddit.com
Adding Conditional Control to Text-to-Image Diffusion Models (ControlNet) (tistory.com)
Adding Conditional Control to Text-to-Image Diffusion Models (ControlNet)
https://arxiv.org/abs/2302.05543 Adding Conditional Control to Text-to-Image Diffusion Models We present ControlNet, a neural network architecture to add spatial conditioning controls to large, pretrained text-to-image diffusion models. ControlNet locks th
bigdata-analyst.tistory.com