
[논문 리뷰] IDM-VTON : Improving Diffusion Models for AuthenticVirtual Try-on in the Wild
paper : [2403.05139] Improving Diffusion Models for Virtual Try-on (arxiv.org)
Improving Diffusion Models for Virtual Try-on
This paper considers image-based virtual try-on, which renders an image of a person wearing a curated garment, given a pair of images depicting the person and the garment, respectively. Previous works adapt existing exemplar-based inpainting diffusion mode
arxiv.org
GitHub - yisol/IDM-VTON: IDM-VTON : Improving Diffusion Models for Authentic Virtual Try-on in the Wild
IDM-VTON : Improving Diffusion Models for Authentic Virtual Try-on in the Wild - yisol/IDM-VTON
github.com
현재 데모 버전으로 제공 중
IDM VTON 플레이그라운드 - IDM VTON 온라인을 무료로 사용해 보세요 | idmvton.com
IDM VTON 플레이그라운드 - IDM VTON 온라인을 무료로 사용해 보세요 | idmvton.com
✨ Upgrade to Premium Plan to enjoy a better unlimited wardrobe experience!
idmvton.com
데모 사용해서 써봄. 예시로 올라와있는 사진을 사용했는데 대략 10초 좀 오버되게 걸리는 듯 하다

Abstract
Image VTON = image-based virtual try-on = 이미지 기반 가상 착용
: 사람과 의상을각각 묘사한 한 쌍의 이미지가 주어지면 큐레이션된 의상을 입은 사람의 이미지를 렌더링
기존 연구
- exemplar-based inpainting diffusion model을 virtual try-on(가상 착장)에 적용해 다른 방법(GAN 기반)에 비해 생성된 비주얼의 자연스러움을 개선함
- 의상의 정체성을 보존하지 못한다는 단점 존재
=> 의상의 충실도 개선(세부 사항 더 잘 보존함) & 실제와 같은 가상 착장 이미지를 생성하는 새로운 diffusion model인 'IDM-VTON' 제안
IDM-VTON
- 두 가지 모듈 사용해 의복 이미지의 semantics을 인코딩
- UNet이 base로 주어지면 1) visual encoder에서 추출한 high-level의 semantics을 cross-attention layer에 융합한 다음 2) parallel UNet에서 추출한 low-level semantics을 self-attention layer에 융합함
- 생성된 visual의 사실성을 높이기 위해 의상과 인물 이미지 모두에 상세한 text prompt를 제공함
- pair로 구성된 사람과 의상의 이미지(person-garment images)를 사용 -> 충실도와 사실성 향상시키는 커스터마이징 기법 제공
Introduction
Image-based VTON
- 주어진 특정 의상을 임의의 인물에게 입힌 이미지를 시각적으로 렌더링하는 것이 목표인 CV 작업
- VTON의 핵심 과제 : 의상의 패턴과 질감에 왜곡을 일으키지 않으면서 다양한 포즈나 제스처를 취하는 인체에 의상을 맞추는 것
- 이때 GAN 기반의 방법은 왜곡을 발생하기 쉬움 -> 최근의 diffusion 모델은 GAN에 비해 우수한 성능 보임
Diffusion model
- 의상의 세부 사항을 식별하기 위해 의상의 semantics를 psedowords로 인코딩하거나 명시적 warping network를 사용함
- 그러나 이러한 방법은 패턴, 질감, 모양 또는 색상 등의 의상의 세밀한 디테일을 보존하는데 부족함
=> 논문에서는 이러한 한계를 극복하기 위해 IDM-VTON을 제안함
IDM-VTON의 특징
1) 의상의 high-level semantics을 인코딩하는 image prompt adapter = IP-Adapter
2) 세밀한디테일을 보존하기 위해 low-level semantics을 추출하는 UNet encoder = GarmentNet
3) single pair of garment and person images를 사용해 모델을 커스터마이징하는 방법을 제안함 -> 이미지의 시각적 품질 향상(특히 wild scenario에서)
4) 의류 이미지에 대한 상세한 캡션 제공 -> T2I diffusion model의 prior knowledge를 유지하는 것의 중요성을 보임
- 상세한 캡션(예: 소매 길이, 목선 모양, 아이템 종류 등). 모델이 더 정확하고 자연스러운 이미지를 생성하는 데 기여함.
Method
1. Backgrounds on Diffusion Models
Diffusion models
: 데이터에 Gaussian noise를 점진적으로 추가하는 forward process & 무작위로 noise를 점진적으로 제거해 샘플을 생성하는 reverse process로 구성되는 generative model
- x_0 : data point (예: image or output of autoencoder인 latent)
- noise schedules
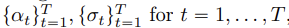
- forward process

이때 충분히 큰 sigma_t와 x_t는 pure random Gaussian noise와 다르지 않다.

- reverse process
: data distribution에 따라 x_t에서 initialized되고 x_t에서 x_0로 denoise된다.

Text-to-image (T2I) diffusion models
: pretrained text encoder (ex: T5, CLIP text encoder)를 사용해 임베딩으로 인코딩된 텍스트에 조건부 이미지의 분포를 모델링하는 diffusion model
- diffusion model을 위해 convolutional UNet이 개발되었지만, 최근 연구에서는 UNet을 위해 transformer architectures를 융합할 수 있다는 가능성을 보여줌
- diffusion model의 training은 perturbed data distribution의 score function과 동등(equivalent)한 것으로 나타났는데, 이는 ϵ-noise prediction loss으로 드러남
- data x_0와 text embedding c가 주어졌을 때, T2I diffusion model의 training loss


- classifier-free guidance (CFG) 사용 <- unconditional과 conditional 함께 학습
- training 단계에서 text conditioning은 무작위로 dropped out되고(=input에 null-text를 제공), inference 단계에서 CFG는 조건부 및 무조건 noise output을 보간해 text conditioning의 강도를 제어함


Image prompt adapter
본 논문에서는 reference image로 T2I diffusion model을 conditioning하기 위해 image encoder(예: CLIP image encoder)에서 추출한 feature를 활용하고 text conditioning에 추가적인 cross-attention layer를 attach하는 image prompt adapter (IP-Adapter)를 제안함
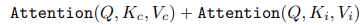
- 원본 UNet을 고정하고(freezes), image embedding의 key & value값 매트릭스의 projection layer와 CLIP image embedding을 매핑하는 linear projection layer만 fine-tuning함
- 𝑄 : UNet의 중간 표현으로부터 추출된 쿼리 행렬
- 𝐾𝑐와 𝑉𝑐 텍스트 임베딩 𝑐로부터의 키 및 값 행렬
- IP-Adapter는 이미지 임베딩 𝑖로부터의 키 및 값 행렬 𝐾𝑖와 𝑉𝑖를 계산하고, 이를 cross-attention layer에 삽입함
2. Proposed Method
VTON을 위한 diffusion model을 설계하는 방법
- x_p : 사람 이미지 (image of a person)
- x_g : 의상 이미지 (image of a garment)
- x_tr : 사람 x_p가 의상 x_g를 입은 이미지
=> x_tr을 생성해내는 것이 목표
masked image를 reference image로 채우는 것을 목표로 하는 exemplarbased(예시 기반) image inpainting 문제로 VTON을 캐스팅하는 것이 일반적인 관행임
-> 의상의 정보를 추출하고 diffusion model에 conditional controls를 추가하는 것이 중요함
이를 위해 IDM-VTON은 아래의 세 가지로 이루어져있다.
1) TryonNet : masked person image를 pose information으로 처리하는 기본 UNet
2) IP-Adapter : 의상의 high-level semantics을 추출하는 image prompt adapter
- high-level semantics :이미지의 전체적인 context나 특징 설명함.
- 예: 의류 종류(티셔츠, 바지...), 스타일(캐주얼, 정장...), 소매 길이(반소매, 긴 소매 등)
3) GarmentNet : 의상의 low-level semantics를 추출하는 garment UNet feature encoder
- low-level semantics : 이미지의 세부적인 텍스처, 미세한 특징
- 예: 질감(면, 실크...), 텍스처 세부 사항(의류의 재질감, 표면 디테일)
=> GarmentNet이라는 추가 UNet 인코더로 추출된 low-level feature들은 TryonNet의 self-attention layer에서 융합되고, cross-attention layer를 통해 IP-Adapter의 feature들과 함께 처리됨
Overview of IDM-VTON
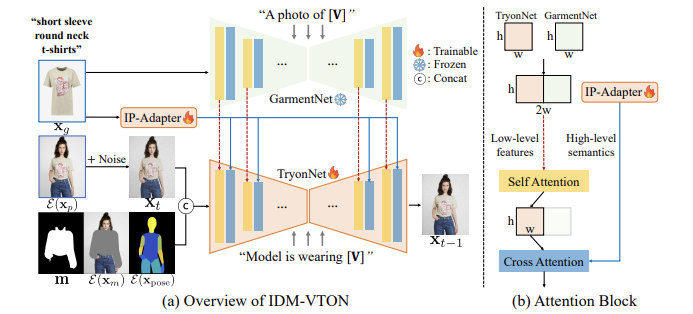
(a) Overview of IDM-VTON
x_p를 처리하는 메인 UNet인 TryonNet, x_g의 high-level semantics를 인코딩하는 IP-Adapter, x_g의 low-level features를 인코딩하는 GarmentNet으로 구성돼있음.
1) UNet에 대한 input으로 noised latent x_t를 segmentation mask m, masked image, densepose와 연결함
- 의상에 대한 자세한 캡션(위의 [V]) 제공 (예: [V]: “short sleeve round neck t-shirts”)
2) 그 후 GarmentNet(예: “a photo of [V]”)과 TryonNet(예: "Model is wearing [V]”)의 입력 프롬프트에 사용됨
- GarmentNet 입력 프롬프트: "A photo of [V]"
- TryonNet 입력 프롬프트: "Model is wearing [V]"
(b) Attention Block
1) TryonNet과 GarmentNet의 중간 피처를 연결하여 self-attention layer로 전달하고 output으로 나온 전반부(주로 TryonNet의 피처를 포함함. fist half) 피처를 IP-Adatper의 input으로 사용함
- TryonNet의 중간 피처 : 주로 인체의 모양과 포즈 정보 포함
- GarmentNet의 중간 피처 : 의상의 low-level detail(예: 텍스처, 패턴)을 포함
- 연결된 중간 피처는 사람 이미지와 의상 이미지 정보를 모두 포함함
2) cross-attention layer를 통해 text encoder과 IP-Adapter의 피처와 output을 융합함
- IP-Adatper는 텍스트 인코더와 CLIP 이미지 인코더로부터 추출된 high-level semantics를 결합해 최종 피처를 생성함. high-level semantics과 low-level features를 효과적으로 융합함. 의류 이미지의 고수준 의미론적 특성을 추출하고 이를 모델에 융합하는 역할을 함
- TryonNet과 IP-Adapter 모듈을 finetuning하고 다른 components는 freeze시킴
TryonNet
기본 UNet 모델로서, 본 논문에서는 latent diffusion model을 고려함
- diffusion generative modeling은 VAE의 latent space에서 수행되고, output은 디코더 D로 전달되어 이미지를 생성함.
- 기본 UNet의 input으로 아래의 네 가지 구성 요소를 결합함
1. latent of person image (사람 이미지의 잠재 표현)

2. mask m that removes the garment on the person image (사람 이미지에서 의류를 제거한 크기가 조정된 마스크 m)
3. the latent of masked-out person image (마스크된 사람 이미지)

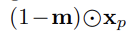
4. the latent of the Densepose [9] xpose of a person image (사람 이미지의 densepose인 x_pose의 잠재 표현)

- 그 후 잠재 표현들을 채널 축을 따라 정렬함
- 이떄 UNet의 합성곱 층을 13 채널로 확장하고 초기값은 모두 0으로 설정함
- 기존의 VTON diffusion model과 달리 본 논문에서는 SDXL inpainting model을 활용함
Image prompt adapter
high-level semantics를 의상 이미지에 조건화하기 위해 image prompt adapter(IP-Adapter)를 사용함
1) CLIP image encoder(OpenCLIP ViT-H/14)로 의상 이미지의 피처 추출
2) feature projection layers와 cross-attention layers를 fine-tune -> pretrained된 IP-Adapter로 초기화됨
-> 텍스트 임베딩과 이미지 임베딩을 결합함
3) 최종적으로 결합된 이 feature는 UNet의 중간 피처와 융함되어 high-level semantics를 반영함
GarmentNet
- IP-Adapter로 이미 의상 이미지를 조건화했지만, 복잡한 패턴이나 그래픽 프린트가 있는 의상의 세부 사항을 보존하는 데에는 한계가 존재함 -> 의상 이미지의 low-level feature를 추출해 모델의 정확도를 높이는 역할 = GarmentNet
- CLIP image encoder가 의류의 low-level feature를 추출하는 데 한계가 있기 때문
=> 추가적인 UNet encoder (GarmentNet)을 사용해 의상 이미지의 세부 사항을 인코딩함

1) 의상 이미지의 잠재 표현 epsilon(x_g)가 주어진 상태에서 pretrained UNet encoder를 통해 중간 표현(representation)을 얻고, TryonNet의 중간 표현과 결합함
- SDXL의 UNet을 활용해 pretrained T2I diffusion model의 prior 지식을 최대한 활용함
2) 결합된 특징에서 self-attention을 계산함. 이과정에서 TryonNet의 첫 번째 절반 차원만을 사용해 중요한 feature를 강조함
Detailed captioning of garments
대부분의 diffusion-based VTON
: pretrained T2I diffusion model을 활용하지만, text prompt를 input으로 사용하지 않거나 단순한 text prompt(예: "upper garment")를 사용함
=> 본 논문에서는 T2I diffusion model의 prior 지식을 사용하기 완전히 활용하기 위해 의류의 디테일(예: 형태나 이미지)을 설명하는 포괄적인 캡션을 제공함

- 상세한 캡션을 제공함으로써 모델이 의류의 high-level semantics를 더 잘 이해하고, 더 정밀하고 자연스러운 이미지를 생성할 수 있도록 도움
Customization of IDM-VTON
본 모델이 의류의 detail을 잘 캡쳐할 수 있지만, 사람 이미지 x_p와 의류 이미지 x_g가 training distribution와 다른 새로운 데이터일 때 어려움이 발생할 수 있음
-> 한 쌍의 의류-사람 이미지를 TryonNet에서 사용해 fine-tuning함으로 IDM-VTON을 효과적으로 커스터마이징해 새로운 데이터에서도 잘 작동함을 확인함
- 한 쌍의 x_p와 x_g 이미지를 모두 가지고 있을 때 : IDM-VTON 간단히 fine-tune
- $x_p$만 존재 : 의상 $x_g$를 segment하고 배경 하얗게 처리해 x_g 얻음(생성)

- TryonNet의 디코더 레이어만 파인튜닝하며, 이는 실험적으로 잘 작동함
Experiment
dataset : VITON-HD & DressCode & In-the-Wild 데이터셋 사용
- VITON-HD는 11,647개의 훈련 이미지 쌍과 1,224개의 테스트 이미지 쌍을 포함하고 있으며, 주로 간단한 포즈와 단색 배경을 특징으로 함
- DressCode는 17,032개의 훈련 이미지 쌍과 2,041개의 테스트 이미지 쌍을 포함하며, 다양한 패턴과 복잡한 배경을 특징으로 함
- In-the-Wild 데이터셋을 사용하여 다양한 패턴과 로고가 포함된 복잡한 배경에서의 성능을 평가함
정량적 평가 결과, IDM-VTON은 모든 평가 지표에서 기존 방법들보다 우수한 성능을 보였으며, 정성적 평가 결과에서도 다양한 상황에서 고품질의 가상 착용 이미지를 생성하는 데 성공함.
특히, GarmentNet과 커스터마이징 기법이 모델의 성능 향상에 크게 기여함을 확인함.
왜 내 tistory에는 LATex가 적용이 안될까....