
간략하게 정리해두는 게 좋을 거 같아 휘리릭 써봄
stable diffusion을 fine-tuning하는 방법들이다. 간략히 설명하면 아래와 같다.
- Textual Inversion : text encoder에 새로운 words를 적은 데이터셋으로 학습할 수 있음
- Dreambooth : UNet을 fine-tunes 할 수 있는 방법
- Full Stable Diffusion fine-tuning : 충분한 데이터셋이 있을 때 사용
즉, Textual Inversion과 DreamBooth는 둘 다 pretrained text-to-image 모델을 personalization하는 기술인데, 그 방법에서 차이가 존재하는 것이다.
1. Textual Inversion
: 유저가 object나 style과 같은 concept에 대해 제공한 3-5장의 이미지만으로 그것을 표현하는 embedding space에서의 새로운 “단어”들을 학습하는 방법론
- 특히, 저자들은 single word embedding이 유니크하고 다양한 concept을 capture하기에 충분하다는 증거를 찾아냄
새로운 개념을 대규모 모델에 도입하는 것은 어려움
- retraining은 비용이 많이 들고, fine tuning은 기존의 것을 망각할 위험이 존재함 (Language drift)
-> 저자들은 pretrained된 T2I model들의 texual embedding space에서 새로운 단어(word)를 찾음으로 이러한 문제를 극복할 것을 제안 - 새로운 concept인 입력 이미지를 나타내는 S*를 표현하는 방법을 찾는 것이 모델의 목표이며, 생성모델을 변경하지 않은 채로 S*를 다른 일반적인 words처럼 처리하는데, S*을 정의하는 과정을 “Textual Inversion”
- This embedding is found through an optimization process, which we refer to as "Textual Inversion".

text encoding process의 첫 stage를 고려함
"A photo of S*"라는 입력 문자열(input string)은 tokenizer를 지나면서 각각 "508", "701", "73", "*"과 같은 형태의 token set으로 변환되고, 이후 각 토큰은 자체 embedding vector로 변환됨
이러한 벡터는 downstream model로 fed 됨
본 논문은 특정 concept에 대한 새로운 pseudo-words(입력된 모르는 단어)인 S*를 찾아 새로운 embedding vector(V*)를 나타내는 것이 목적!
- 생성을 가이드할 수 있는 pseudo-word를 찾는 것이 목표
- S*로 새로운 임베딩 벡터를 표현함. 그 후 이 psedo-word는 다른 단어와 마찬가지로 다루어지고 생성 모델에 대한 새로운 텍스트 쿼리를 작성하는 데 사용됨
- ex : “ a photograph of on the beach ”
- ex2 : “a drwaing of 𝑆∗1 in the style of 𝑆∗2” <- 두 가지 concept으로 구성할 수도 있음
- 따라서 이 query는 generator에 들어가서 사용자가 의도한 바와 일치하도록 새로운 image를 생성하도록 하는 것
= 새로운 user-specified concepts에 대한 language-guided generation
이러한 pseudo-word(유사단어)를 찾기 위해 본 논문에서는 task를 하나로 inversion시켜 프레임화함
주어진 pre-trained T2I model 모델과 concept을 나타내는 small(3-5) image set가 주어질 때, 저자들은 “A photo of 𝑆∗”과 같은 형태의 문장을 설정해서 주어진 작은 dataset에서 이미지를 재구성하는 것으로 이어지는 single-word embedding을 찾는 것을 목표로 함
이 embedding은 optimization process를 통해 찾아질 수 있고, 이를 Textual Inversion이라 부름
- 이때 이 과정에서 생성모델(본 논문에서는 LDM)은 untouched되어 있음(따로 수정이 들어가지 않음)
-> 새로운 task에 대한 fine-tuning을 할 때 일반적으로 손실되는 text 이해도나 generalization을 유지할 수 있음
- CLIP-based reconstruction에서, 본 논문의 method가 unique detail과 concept을 잘 capture함

context text를 𝑆∗로 대체하여, style transfer 역시 가능
동시에 여러 word를 추론할 수 있지만, 새로운 word간의 관계 추론에는 어려움을 겪음
2. Dreambooth
: DreamBooth는 3~5장의 이미지를 이용하여 모델을 fine-tuning하고, 주어진 컨셉을 나타내는 Unique Identifier, 즉 고유 식별자([V])를 사용하여 이미지를 합성함
기존의 모델들 : key visual features에 대한 높은 충실도를 유지하면서 새로운 맥락의 사진을 생성하는 것이 어려움
large T2I 모델들은 대규모의 이미지-캡션 데이터셋에서 학습되었기 때문에, strong semantic prior를 가지고 있기 때문
-> 몇 장의 이미지로 T2I 모델을 fine-tuning 하면서도, 기존 모델의 semantic knowledge를 보존하는 것이 DreamBooth의 목적
- DreamBooth는 기존의 fine-tuning과는 달리 적은 수의 이미지만으로 모델의 오염(overfitting, language drift)없이 학습이 가능하기 때문에 개인이 더 손쉽게 fine-tuning이 가능하다는 장점이 존재함
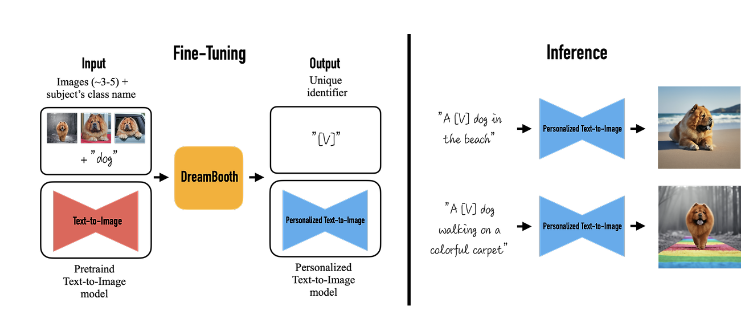
input으로 몇장 이미지와 대상에 대한 class 이름이 주어지며 이를 DreamBooth를 통해 fine-tuning하면, [V]에 대해 학습된 personalized T2I model이 output으로 나오게 되는 것
- ex : 이미 여러 동물에 대해 학습된 어떤 pretrained model이 존재할 때, 내가 키우는 개를 학습시키고 싶음
-> 학습 이미지 : 내가 키우는 개 [V] 에 대한 사진, class name : "dog"- dog 말고 더 상위 개념인 animal로 정해도 되지만 너무 포괄적이기에 모든 animal의 특성이 [V]와 섞이게 되어 좋지 못한 결과물이 나올 가능성이 높아질 것

모델은 fine-tuning 과정에서 사용자가 생성하고자 하는 특정 subject와 "새로운 단어"(unique identifier)를 함께 학습함
few-shot dataset으로 subject-identifier를 학습하고 아래에서는 기존 모델이 생성한 이미지를 학습하여 사전 지식을 유지함
- "A [V] dog" 처럼 unique identifier와 클래스 이름이 합쳐진 텍스트 프롬프트를 사용해서 파인튜닝함
- prompt로 "[identifier] [class noun]" 의 형태를 이용
- [identifier] : subject를 의미하는 unique identifier
- [class noun] : subject의 class를 대략적으로 설명하는 단어. 모델의 사전 지식을 활용하여 훈련 시간을 줄이고 성능을 향상시키는 역할 ex) dog, cat, watch
- 하지만 이렇게만 학습을 진행하면 language drift 현상 발생
-> 따라서 논문의 저자들은 이를 방지하기 위해서 클래스에 대한 semantic prior를 활용하는 autogenous, class-specific prior preservation loss도 제안
연구진들은 모델의 vocabulary에서 희귀 토큰을 찾아 text space로 변환하는 방식으로 unique token을 선택함
희귀 토큰 𝑓(𝑉^)를 찾고 대응하는 단어 𝑉를 unique identifier로 사용함
- 모델이 단어를 원래의 의미로부터 분리하고 컨셉과 연결되도록 학습해야 함
-> 따라서 특별한 의미를 가지지 않는 단어를 활용하는 것이 효율적임- 무작위 알파벳으로 구성된 "xxy5syt00"와 같은 단어는 tokenizer에 의해 각 글자별로 토큰화되기 때문에 마찬가지로 좋지 않은 선택임
기존 모델의 내용을 유지하면서 새로운 것을 학습할 때 DreamBooth는 class image(Regularization image, 정규화 이미지)를 사용함
학습하고 싶은 이미지인 A [V] dog에 대한 input image를 학습하과 동시에 기존 모델이 이용해 출력한 A dog라는 class name에 대한 이미지인 class image를 같이 학습해 기존 모델이 가진 class name에 대한 지식을 잊지 않도록 함
- 학습에 class-specific prior preservation loss라는 자체적인 손실 함수 이용함
- 기존 diffusion model의 손실함수와의 차이점은 +뒤의 term이 추가되었다는 것인데, lambda와 class image에 대한 손실함수를 곱하였기 때문에 lambda 값을 조절해 가중치에 어느정도로 class image의 손실함수를 추가할지 조절이 가능

Textual Inversion
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Text-to-image models offer unprecedented freedom to guide creation through natural language. Yet, it is unclear how such freedom can be exercised to generate images of specific unique concepts, modify their appearance, or compose them in new roles and nove
arxiv.org
github : rinongal/textual_inversion (github.com)
GitHub - rinongal/textual_inversion
Contribute to rinongal/textual_inversion development by creating an account on GitHub.
github.com
Dreambooth
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
Large text-to-image models achieved a remarkable leap in the evolution of AI, enabling high-quality and diverse synthesis of images from a given text prompt. However, these models lack the ability to mimic the appearance of subjects in a given reference se
arxiv.org
[Generative] Diffusion-based Inversion과 Personalization에 대한 생각 (tistory.com)
'논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] Llama 2 (0) | 2024.07.30 |
|---|---|
| [논문 리뷰] YOLO (You Only Look Once: Unified, Real-Time Object Detection) (1) | 2024.07.13 |
| [논문 리뷰] LoRA : Low-Rank Adaptation of Large Language Models (0) | 2024.07.13 |
| [논문 리뷰] IDM-VTON : Improving Diffusion Models for AuthenticVirtual Try-on in the Wild (0) | 2024.05.31 |
| [논문 리뷰] NCSN: Generative Modeling by Estimating Gradients of the Data Distribution (0) | 2024.05.24 |