Diffusers : 모든 메모리, 컴퓨팅, 품질 개선과 함꼐 안정적인 Diffusion을 실행할 수 있는 간단한 API를 제공한다.
Stable Diffusion을 이 Diffusers를 이용해 추론(inference)을 위한 pipeline을 차례로 구축해볼 수 있었다.
참고한 자료는 아래와 같다.
The Stable Diffusion Guide 🎨 (huggingface.co)
The Stable Diffusion Guide 🎨
Taking Diffusers Beyond Images
huggingface.co
Prompt Engineering
추론에서 Stable diffusion을 실행할 때는 일반적으로 특정 타입 또는 스타일의 이미지를 생성한 다음 이를 개선하고자 한다. 이전에 생성된 이미지를 개선한다는 것은 만족할 때까지 다른 프롬프트와 잠재적으로 다른 seed를 사용하여 추론을 반복해 실행하는 것을 의미한다. 따라서 우선은 SD의 속도를 최대한 높여 주어진 시간 내에 최대한 많은 사진을 생성하는 것이 가장 중요하다. 이는 계산 효율성(속도)과 메모리 효율성(GPU RAM)을 개선함으로써 달성할 수 있다.
model_id = "runwayml/stable-diffusion-v1-5" # 예시 모델 ID
runwayML에서개발한 SD의 1.5 version이다.
Speed Optimization
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained(model_id)
- StableDiffusionPipeline.from_pretrained(model_id) : 사전 훈련된 stable diffusion 모델을 로드함. 모델의 가중치와 설정이 로컬 환경 또는 지정된 경로에 저장됨. 로드된 모델을 바탕으로 "StableDiffusionPipeline" 객체가 초기화됨.
- pipe : 텍스트-이미지 변환 모델의 파이프라인을 나타내는 객체. 프롬프트로 텍스트 입력을 받아 이미지를 생성하는 전체 과정(데이터 전처리, 모델 추론, 후처리 등)을 캡슐화함.
prompt = "portrait photo of a old warrior chief"
pipe = pipe.to("cuda") # GPU 사용을 위해 GPU로 pipe 객체 이동시킴
위의 텍스트 프롬프트를 바탕으로 이미지를 생성할 예정이다.
generator = torch.Generator("cuda").manual_seed(0)
모든 call에서 거의 동일한 이미지를 재현할 수 있도록 하기 위해 generator를 사용한다. PyTorch에서 사용되는 난수 생성기(torch.Generator)를 초기화하고, 이를 seed 0으로 고정한다.
- torch.Generator("cuda") : cuda 환경(즉, NVIDIA GPU)에서 작동하는 새로운 난수 생성기 인스턴스를 사용함.
- manual_seed(0) : generator의 시드값을 0으로 설정함으로써 실험의 재현성을 보장함.
image = pipe(prompt, generator = generator).images[0]
image
사용자가 입력한 텍스트 설명에 따라 생성된 이미지들 중 첫 번째 이미지를 선택해 image 변수에 할당한다.
- images[0] : pipe 함수가 반환하는 객체에서 이미지 리스트를 참조하고, 그 중 첫번째 이미지를 선택하는 것 의미함.
- pipe : 입력된 프롬프트를 기반으로 하나 이상의 이미지를 생성하고, 이 이미지들이 .images라는 리스트 또는 배열 안에 저장됨. 딥러닝 모델, 특히 자연어 처리나 이미지 생성과 같은 과제에서 사용되는 고수준의 API.
- pipe 함수는 특별히 생성할 이미지의 수를 지정하는 매개변수(예: num_image)를 설정하지 않는 경우, 대부분의 구현에서는 기본적으로 하나의 이미지만 생성함.
- inference_step은 생성 과정에서 모델이 거치는 추론 단계의 수를 의미하는 것임. 디폴트는 50으로, 이는 한 번의 이미지 생성 요청에 대해 모델이 50번의 연산을 수행한다는 것을 의미함! 생성할 이미지 수와는 다른 개념임.
- inference_step은 하나의 이미지를 생성하는 데 있어서의 추론 과정의 복잡성 또는 깊이를 나타내는 것.
- .images[0]은 생성된 유일한 이미지에 접근하는 것을 의미함!
- pipe 함수는 특별히 생성할 이미지의 수를 지정하는 매개변수(예: num_image)를 설정하지 않는 경우, 대부분의 구현에서는 기본적으로 하나의 이미지만 생성함.

여기까지 수행한 기본 실행은 전체 float32 정밀도를 사용하고, 기본 inference_step을 50으로 사용한 형태이다(50이 디폴트값임). 여기서 더 쉽게 속도를 높이는 방법은 float16(또는 절반) 정밀도를 사용하고 추론 단계를 더 적게 실행하는 것이다. 아래는 모델을 float16으로 로드한 것이다.
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype = torch.float16)
pipe = pipe.to("cuda")
generator = torch.Generator("cuda").manual_seed(0)
image = pipe(prompt, generator = generator).images[0]
image
float32인 경우보다 거의 3배나 빠른 속도이다. 이때까지 float16으로 인해 품질이 저하되는 경우는 거의 없었으므로 항상 float16으로 파이프라인을 실행할 것을 권장한다.
+ ) hugging face의 결과는 동일한 이미지가 생성되는 것이었는데, 나의 경우 float32일 때와 float16일 때의 이미지가 서로 다르게 생성되었다. float16을 사용할 때의 속도 향상은 명확하지만, 이는 정밀도의 손실과 수치 안정성의 감소를 수반할 수 있으며 이로 인해 최종 생성된 이미지에 차이가 발생할 수 있다고 한다. 이에 고정된 시드 값에도 불구하고 다른 이미지가 생성된 것이다.
추가로 inference step을 50으로 사용해야 하는지, 훨씬 더 적은 단계를 사용해도 되는지를 살펴볼 수 있다.
추론 단계의 수는 우리가 사용하는 denoising scheduler과 관련이 있다. 보다 효율적인 scheduler를 사용하면 step 수를 줄이는 데에 도움이 될 수 있다.
inference step이 많을수록 모델은 더 많은 계산을 수행해 이미지의 세부 사항을 더욱 정교하게 만들 수 있으나, 그만큼 처리 시간도 더 길어진다. 반대로 inference step을 줄이면 이미지 생성 속도는 빨라지지만, 결과 이미지의 품질이 떨어질 수 있다.
pipe.schedulers.compatibles[diffusers.schedulers.scheduling_ddim.DDIMScheduler,
diffusers.utils.dummy_torch_and_torchsde_objects.DPMSolverSDEScheduler,
diffusers.schedulers.scheduling_edm_euler.EDMEulerScheduler,
diffusers.schedulers.scheduling_deis_multistep.DEISMultistepScheduler,
diffusers.schedulers.scheduling_euler_discrete.EulerDiscreteScheduler,
diffusers.schedulers.scheduling_heun_discrete.HeunDiscreteScheduler,
diffusers.schedulers.scheduling_euler_ancestral_discrete.EulerAncestralDiscreteScheduler,
diffusers.schedulers.scheduling_ddpm.DDPMScheduler,
diffusers.schedulers.scheduling_k_dpm_2_ancestral_discrete.KDPM2AncestralDiscreteScheduler,
diffusers.schedulers.scheduling_dpmsolver_multistep.DPMSolverMultistepScheduler,
diffusers.schedulers.scheduling_lms_discrete.LMSDiscreteScheduler,
diffusers.schedulers.scheduling_dpmsolver_singlestep.DPMSolverSinglestepScheduler,
diffusers.schedulers.scheduling_unipc_multistep.UniPCMultistepScheduler,
diffusers.schedulers.scheduling_pndm.PNDMScheduler,
diffusers.schedulers.scheduling_k_dpm_2_discrete.KDPM2DiscreteScheduler]
위 코드를 통해 사용할 수 있는 모든 scheduler를 볼 수 있다.
현재 SD에서는 일반적으로 PNDMScheduler를 사용하고 있는데, 이는 약 50 단계의 추론을 요구한다. 그러나 DPMSolverMultistepSheduler 또는 DPMSolverSinglestepsScheduler와 같은 다른 스케줄러는 약 20~25개의 추론 단계를 요구한다. config 함수를 통해 다른 스케줄러로 설정할수 있다.
from diffusers import DPMSolverMultistepScheduler
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
generator = torch.Generator("cuda").manual_seed(0)
image = pipe(prompt, generator = generator, num_inference_steps = 20).images[0]
image
이미지는 50 step의 경우보다는 달라졌으나 여전히 고품질이다. 또한 inference 시간이 4초로 단축되었다.
Memory Optimization
간접적으로 generation에 사용되는 메모리가 적다는 것은 더 속도가 빠르다는 것을 의미한다. 이는 초당 생성할 수 있는 이미지 수를 최대화하려고 하는 경우가 많기 때문이다. 일반적으로 추론 실행 당 이미지 수가 많을수록 초당 이미지 수도 많아진다.
한 번에 얼마나 많은 이미지를 생성할 수 있는지 확인하는 가장 쉬운 방법은 간단히 시도해보고 '메모리 부족(OOM)' 오류가 발생하는지 확인하는 것이다.
프롬프트와 generator 목록을 전달하기만 하면 일괄 추론을 실행할 수 있다. 일괄 처리를 생성하는 빠른 함수를 정의하면 아래와 같다.
def get_inputs(batch_size = 1):
generator = [torch.Generator("cuda").manual_seed(i) for i in range(batch_size)]
prompts = batch_size * [prompt]
num_inference_steps = 20
return {"prompt": prompts, "generator": generator, "num_inference_steps" : num_inference_steps }
- manual_seed(batch_size)가 아닌, for i in range(batch_size)를 사용하는 이유
: 여기서 batch_size는 생성할 이미지의 수를 나타낸다. 루프를 사용해 각 난수 생성기에 고유한 시드 값을 ("i") 제공함으로써, 각 생성기는 서로 다른 난수 시퀀스를 생성하게 된다.
만약 manual_seed(batch_size)를 사용하게 되면, 모든 난수 생성기에 대해 동일한 시드 값을 설정하게 되므로, 각각의 난수 생성기가 동일한 난수 시퀀스를 생성하게된다. 이는 배치 처리 과정에서 각 요청 또는 항목에 대해 고유한 난수 시퀀스를 제공하고자 할 때 문제가 될 수 있다.
예로, 이미지 생성 작업에서 각 이미지에 약간의 변화를 주기 위해 난수를 사용한다고 가정할 수 있다. 만약 모든 난수 생성기에 동일한 시드 값을 사용한다면, 모든 이미지에 동일한 변화가 적용되어 다양성이 감소할 것이다.
- promts = batch_size * [prompt] : 주어진 prompt 문자열을 batch_size 만큼 반복해 리스트를 생성함. 이로써 prompts에는 동일한 텍스트 프롬프트가 batch_size 개수만큼 포함됨
- prompt : 이미지 생성이나 다른 작업을 위해 모델에 전달될 텍스트
- [prompt] : prompt 문자열을 단일 요소로 가지는 리스트 생성.
- batch_size * [prompt]: [prompt] 리스트를 batch_size만큼 반복하여 확장함. 예를 들어, batch_size가 3이라면, 결과는 ["a landscape with mountains", "a landscape with mountains", "a landscape with mountains"]와 같은 리스트가 됨.
- 생성된 prompts 리스트는 후속 처리 과정에서 모델의 입력으로 사용될 수도 있으며, 이를 통해 모델은 리스트에 포함된각 프롬프트에 대해 동일한 작업을 수행하게 됨.
아래의 함수는 프롬프트 목록과 generator 목록을 반환하므로 원하는 결과를 생성한 generator를 재사용할 수 있다. 또한 이미지의 배치를 쉽게 표시할 수 있는 method도 필요하다.
from PIL import Image
def image_grid(imgs, rows = 2, cols = 2):
w, h = imgs[0].size # 첫번째 이미지의 너비(w)와 높이(h)를 가져옴.
grid = Image.new("RGB", size = (cols * w, rows * h)) # 새로운 'RGB' 이미지 생성
for i, img in enumerate(imgs): # 각 이미지(img)와 해당 인덱스(i) 가져옴
grid.paste(img, box = (i%cols*w, i//cols*h)) # 각 이미지를 그리드의 적절한 위치에 붙여넣음
return grid # 하나의 큰 그리드 이미지를 반환
- image_grid : 주어진 이미지 리스트 imgs를 사용해 그리드 형태로 배열된 하나의 큰 이미지를 생성하는 함수
- imgs : 합성할 이미지 객체의 리스트
- rows : 그리드에 포함될 행의 수. 기본값은 2임
- cols : 그리드 포함될 열의 수. 기본값은 2임
1. 그리드 이미지 생성
- w, h = imgs[0].size : 첫번째 이미지(imgs[0])의 너비(w)와 높이(h)를 가져옴
- 모든 이미지가 동일한 크기를 가지고 있다고 가정함
- grid = Image.new('RGB', size = (cols * w, rows * h)) : cols * w와 rows * h를 크기로 하는 새로운 'RGB' 이미지 생성함
- 이 이미지는 개별 이미지들을 배치할 그리드 역할을 함
2. 이미지 배치
- grid.paste(img, box=(i%cols*w, i//cols*h)): 각 이미지를 그리드의 적절한 위치에 붙여넣음.
- i%cols*w : 열 내에서 이미지의 x 좌표를 결정함
- i//cols*h : 행 내에서 이미지의 y 좌표를 결정함. 이 계산들을 통해 각 이미지는 그리드 내에서 올바른 위치에 배치됨
3. 결과 반환
- return grid : 모든 이미지를 포함하는 하나의 큰 그리드 이미지를 반환함
위 함수는 여러 이미지를 한 번에 시각적으로 표시하고 싶을 때 유용하게 사용할 수 있다. 그 예로, 이미지 처리 과정의 중간 결과나 여러 샘플 이미지를 한눈에 비교하기 위한 용도로 사용할 수 있다.
아래 코드로 batch_size= 4로 설정해 얼마나 많은 메모리를 사용할 수 있는지 살펴볼 수 있다.
imgaes = pipe(**get_inputs(batch_size = 4)).images
image_grid(images)

노트북의 T4 GPU에서는 batch_size가 4를 초과하면 오류가 발생한다. 또한 초당 이미지 생성 속도가 이전에 비해 약간 더 빨라진 것을 볼 수 있다.
커뮤니티에서 메모리 제약을 더 개선할 수 있는 몇 가지의 유용한 방법을 더 찾아냈는데, 그 중 하나가 바로 아래의 enable_attention_slicing을 호출해 활성화하는 것이다.
지금까지 대부분의 메모리는 cross-attention layers가 차지하는데, 이 작업을 일괄적으로 실행하는 대신 순차적으로 실행하면 상당한 양의 메모리를 절약할 수 있는 것이다.
pipe.enable_attention_slicing()
attention slicing이 활성화되었으므로 배치 크기를 두 배로 늘려서 실행해볼 수 있다.
images = pipe(**get_inputs(batch_size = 8)).images
image_grid(images, rows = 2, cols = 4)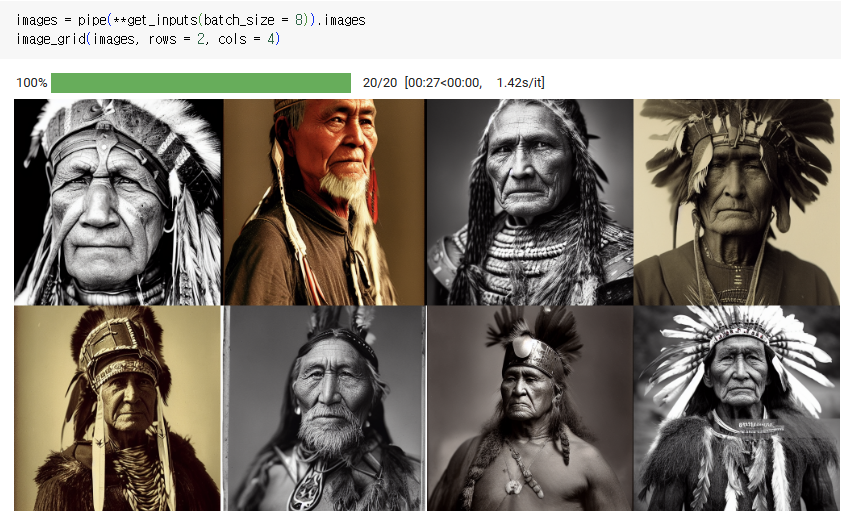
속도 향상이 그리 크지는 않지만, 품질 저하 없이 T4로 얻을 수 있는 가장 빠른 속도이다.
Quality Improvements
위에서 이미지 생성 pipeline의 속도를 개선시키는 방법을 알아보았는데, 이제 이미지 품질을 극대화하는 방법을 알아볼 수 있다.
이미지의 quality는 지극히 주관적이기에 일반적인 주장을 하기에는 어려움이 있으나, 화질을 개선하기 위한 가장 확실한 방법은 더 나은 checkpoints를 사용하는 것이다. SD가 릴리즈된 이후 많은 개선된 버전들이 출시되었는데, 최신 버전이라고 해서 무조건적으로 동일한 매개변수에서 더 나은 이미지 품질을 제공하는 것은 아님을 명심해야 한다. (그 예로 일부 프롬프트의 경우 2.0이 1.5보다 약간 더 나쁘다는 의견이 있지만, 올바른 프롬프트 엔지니어링을 고려하면 2.0과 2.1이 더 나은 것 같다는 의견이 존재한다.) 따라서 전반적으로 모델을 사용해보고 온라인에서 여러 어드바이스들을 참고하는 것이 좋다. (예: 2.0과 2.1에서 가능한 최고의 품질을 얻으려면 부정적인 프롬프트를 사용하는 것이 좋다.)
아래의 코드에서는 새로운 auto-decoder를 사용한다.
from diffusers import AutoencoderKL
vae = AutoencoderKL.from_pretrained("stabilityai/sd-vae-ft-mse", torch_dtype = torch.float16).to("cuda")
pipe.vae = vae
vae를 pipeline으로 사용해 이미지를 생성하면 아래와 같다.
images = pipe(**get_inputs(batch_size = 8)).images
image_grid(images, rows = 2, cols = 4)
아주 사소한 차이인 것 같지만, pipeline으로 vae를 사용했을 때의 이미지가 더 선명하게 생성된 것을 볼 수 있다.
프롬프트 엔지니어링에 대해 조금 더 살펴보면, 이전까지 사용한 원래의 목표는 "portrait photo of an old warrior chief"의 사진을 생성하는 것이었다. 이렇게 생성된 사진보다 좀 더 색을 입히고 인상적인 사진을 만들기 위해선 단서와 더 많은 세부 정보를 추가해 프롬프트를 개선할 수 있다.
프롬프트 엔지니어링을 할 때 기본적으로 생각해야 할 사안은 아래와 같다.
1. 내가 원하는 사진이나 비슷한 사진이 인터넷에 있는가?
2. 내가 원하는 스타일로 모델을 조정하려면 어떤 디테일을 추가해야하는가?
# 프롬프트엔지니어링
prompt += ", tribal panther make up, blue on red, side profile, looking away, serious eyes" # detail
prompt += " 50mm portrait photography, hard rim lighting photography--beta --ar 2:3 --beta --upbeta" # cues
prompt
디테일과 단서들을 프롬프트에 추가해서 다시 이미지를 생성했을 때, 높은 퀄리티의 이미지가 생성됨을 볼 수 있다.
- detail : 이미지의 구체적인 시각적 특성이나 요소 지정
- cue : 이미지 생성 과정에 추가적인 지시를 제공하는 힌트나 신호. 카메라 설정, 조명 방식, 이미지 비율 등

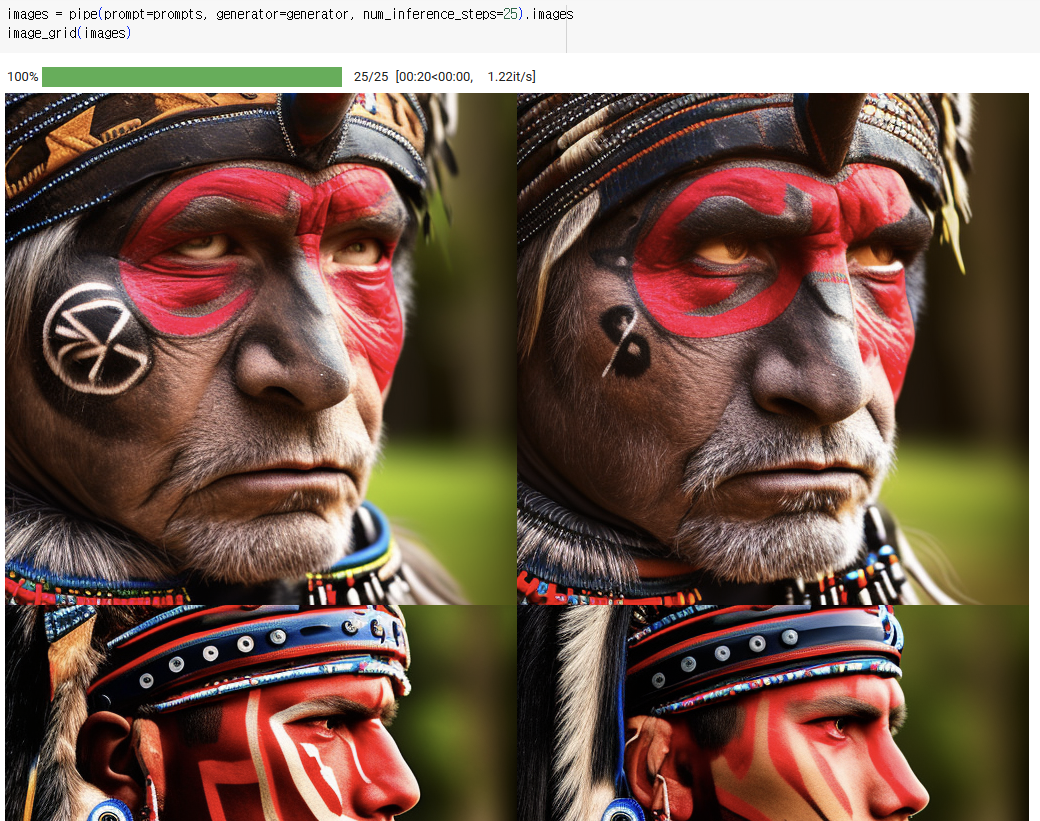
이제 위의 프롬프트의 "oldest warrior", "old" 등의 키워드 속 "old"를 "young"으로 바꿔 이미지를 생성해보았다.
prompts = [
"portrait photo of the oldest warrior chief, tribal panther make up, blue on red, side profile, looking away, serious eyes 50mm portrait photography, hard rim ligting photography--beta --ar 2:3 --beta --upbeta",
"portrait photo of a old warrior chief, tribal panther make up, blue on red, side profile, looking away, serious eyes 50mm portrait photography, hard rim lighting photography--beta --ar 2:3 --beta --upbeta",
"portrait photo of a warrior chief, tribal panther make up, blue on red, side profile, looking away, serious eyes 50mm portrait photography, hard rim lighting photography--beta --ar 2:3 --beta --upbeta",
"portrait photo of a young warrior chief, tribal panther make up, blue on red, side profile, looking away, serious eyes 50mm portrait photography, hard rim lighting photography--beta --ar 2:3 --beta --upbeta"
]
generator = [torch.Generator("cuda").manual_seed(1) for _ in range(len(prompts))]- 각 프롬프트에 대응하는 난수 생성기 인스턴스를 사용해 모든 generator에 동일한 시드(1) 값을 사용해 난수 시퀀스를 일정하게 유지함
images = pipe(prompt=prompts, generator=generator, num_inference_steps=25).images
image_grid(images)
이거 말고도 다른 hugging face도 구현해보면 좋을 거 같다!
구현해본 파일은 아래 깃허브로 볼 수 있다.
https://github.com/alswjd131313/Stable-Diffusion/blob/main/SD_1.ipynb
Stable-Diffusion/SD_1.ipynb at main · alswjd131313/Stable-Diffusion
Contribute to alswjd131313/Stable-Diffusion development by creating an account on GitHub.
github.com
'구현' 카테고리의 다른 글
| [SD] IP-Adapter with multiple image (0) | 2024.05.08 |
|---|---|
| [SD] IP-Adapter with ControlNet (0) | 2024.05.08 |
| [SD] SD with Diffusers (0) | 2024.05.01 |