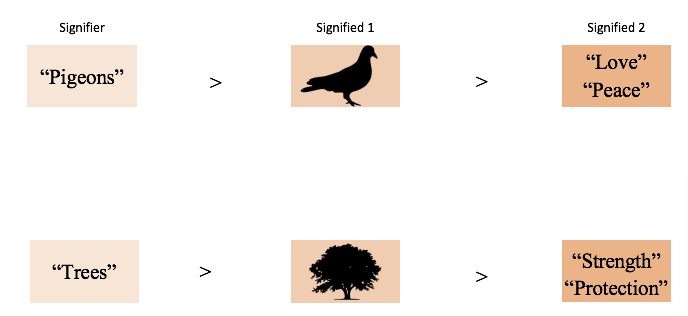
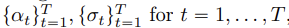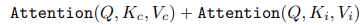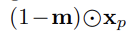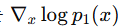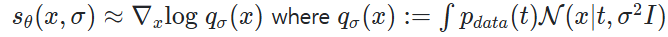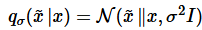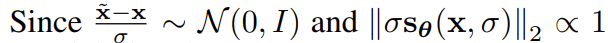유사도 : 해당 단어와 함께 출몰한 주변 단어(context)를 기준으로 결정됨 -> 결국 단어의 "symbols"를 말하는 것이 아닌 단어가 가지고 있는 문법적, 개념적 "의미" (semantics of word meaning)을 나타낼 수 있게 됨
위 가정을 통해 Word2Vec을 적용하면 원핫 벡터가 아닌 유사도 벡터로 표현된 임베디드된 결과를 얻을 수 있게 됨
Word2Vec 추론 처리
중심 단어(center word)로부터 맥락 단어(context word)를 추측하는 용도의 신경망을 사용함 → 이 모델이 가능한 정확하게 추론하도록 훈련시켜서 분산 표현을 얻어냄
추론 : 중심 단어(center word)가 주어졌을 때, 주변 맥락에 무슨 단어가 들어가는지를 추측하는 작업
모델의 input : 중심 단어(center word)
이 중심 단어를 원핫 벡터로 변환하여 모델이 처리할 수 있도록 준비함
입력층이 은닉층을 거쳐 출력층으로 도달
입력층에서 은닉층으로의 변환은 완전연결계층이 처리함
은닉층의 뉴런은 입력층의 완전연결계층에 의해 변환된 값임
입력층에서의 은닉층으로의 변환은 matrix W에 의해 이루어짐. 가중치 W의 각 행에는 해당 단어의 분산 표현이 담겨져 있음. 학습을 진행할수록 맥락에서 출현하는 단어를 잘 추측하는 방향으로 분산표현들이 갱신됨. 이 과정으로 얻은 벡터에는 '단어의 의미'도 잘 녹아있음
출력층의 뉴런은 총 V개 인데, 이 뉴런 하나하나가 각각 단어에 대응함
출력층의 값은 각 단어가 맥락 단어로 나타날 확률을 뜻함
Word2Vec : Prediction Function
𝜃가 optimize될 변수이고, 𝐿은 likelihood, 우도를 가리키며, 때때로 𝐿=𝐽' 임 -> objective function을 minimize 시키는 것이 predictive accuracy를 maximize하는 것이 됨
𝑢 ⃗ _𝑤 : 단어가 context word일때 쓰는 벡터
⃗𝑣_𝑤 : 단어가 center word일때 쓰는 벡터
c : center word
o : context word
optimization을 쉽게 하기 위해 2개의 벡터 개념을 도입
확률은 아래와 같이 계산함
분모 : 확률분포를 제공하기 위해 전체 단어에 대해 정규화(normalize)
분자
exp 사용해 양의 값을 출력하도록 함
괄호 안의 dot product(내적)는 o와 c의 유사도를 계산하는 부분임 -> 대응 단어가 출현할 정도로 해석 가능
larger dot product = larger probability
벡터의 내적 계산을 통해 유사도를 측정하며 이후 softmax 과정을 거쳐 확률을 계산함
Word2Vec: Objective Function
1. Likelihood (가능도)
각 위치 t=1,...,T에서 중심 단어(center word) w_j가 주어졌을 때, 모든 단어에 대해(t) 고정된 크기의 window만큼(j) 주변의 단어 확률을 곱해 크기m으로 고정된 윈도우 안의 맥락 단어(context word) 예측
T : 전체 단어의 개수
t : 단어의 position
m : window size
2. Objective function
가능도를 최대화하는 최적의 파라미터를 찾기 위해 음의 log likelihood를 목적함수(손실 함수)로 만들어 이를 최소화하는 방향으로 단어 벡터를 정함
목적함수 최소화 <=> 다른 단어들의 context에서 중심 단어를 잘 예측함
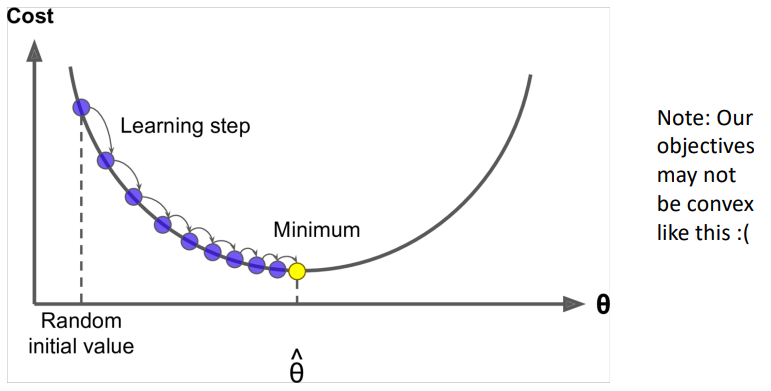
Optimization : Training a model by optimizing parameters
모델을 학습하기 위해, 손실(loss)을 최소화하도록 파라미터를 조정함
=> 최적화 방식을 통해 목적함수를 최소화하는 파라미터 𝜃, 즉 u와 v(word를 나타내는 두 벡터)를 찾음
θ는 모델의 모든 파라미터를 하나의 긴 벡터로 나타냄
V개의 단어가 존재하고 θ가 d-dimension vector일 때, word vector는 u,v를 포함하므로 2dV 차원을 가짐
기울기(gradient)를 따라가면서 이 파라미터들을 최적화함
기울기 유도
Objective funcion:
목적함수를 최소화하기 위해
위 식을 중심 단어(center word), 맥락 단어(context word)로 각각 미분함
미분 과정
이처럼 objective function을 편미분한 것은 실제 단어와 예측한 단어와의 차이와 같음
-> gradient descent를 통해 실제에 더 가깝게 예측할 수 있음
Gradient Desent : J(θ)를 최소화하는 알고리즘
우리는 최소화하고 싶은 비용함수 J(θ)를 가지고 있음
Idea: for current value of θ, calculate gradient of J(θ), then take small step in direction of negative gradient. Repeat.
stable diffusion을 fine-tuning하는 방법들이다. 간략히 설명하면 아래와 같다.
Textual Inversion : text encoder에 새로운 words를 적은 데이터셋으로 학습할 수 있음
Dreambooth : UNet을 fine-tunes 할 수 있는 방법
Full Stable Diffusion fine-tuning : 충분한 데이터셋이 있을 때 사용
즉, Textual Inversion과 DreamBooth는 둘 다 pretrained text-to-image 모델을 personalization하는 기술인데, 그 방법에서 차이가 존재하는 것이다.
1. Textual Inversion
: 유저가 object나 style과 같은 concept에 대해 제공한 3-5장의 이미지만으로 그것을 표현하는 embedding space에서의 새로운 “단어”들을 학습하는 방법론
특히, 저자들은 single word embedding이 유니크하고 다양한 concept을 capture하기에 충분하다는 증거를 찾아냄
새로운 개념을 대규모 모델에 도입하는 것은 어려움
retraining은 비용이 많이 들고, fine tuning은 기존의 것을 망각할 위험이 존재함 (Language drift) -> 저자들은 pretrained된 T2I model들의 texual embedding space에서 새로운 단어(word)를 찾음으로 이러한 문제를 극복할 것을 제안
새로운 concept인 입력 이미지를 나타내는 S*를 표현하는 방법을 찾는 것이 모델의 목표이며, 생성모델을 변경하지 않은 채로 S*를 다른 일반적인 words처럼 처리하는데, S*을 정의하는 과정을 “Textual Inversion”
This embedding is found through an optimization process, which we refer to as "Textual Inversion".
text encoding process의 첫 stage를 고려함
"A photo of S*"라는 입력 문자열(input string)은 tokenizer를 지나면서 각각 "508", "701", "73", "*"과 같은 형태의 token set으로 변환되고, 이후 각 토큰은 자체 embedding vector로 변환됨
이러한 벡터는 downstream model로 fed 됨
본 논문은 특정 concept에 대한 새로운 pseudo-words(입력된 모르는 단어)인 S*를 찾아 새로운 embedding vector(V*)를 나타내는 것이 목적!
생성을 가이드할 수 있는 pseudo-word를 찾는 것이 목표
S*로 새로운 임베딩 벡터를 표현함. 그 후 이 psedo-word는 다른 단어와 마찬가지로 다루어지고 생성 모델에 대한 새로운 텍스트 쿼리를 작성하는 데 사용됨
ex : “ a photograph of S∗ on the beach”
ex2 : “a drwaing of 𝑆∗1 in the style of 𝑆∗2” <- 두 가지 concept으로 구성할 수도 있음
따라서 이 query는 generator에 들어가서 사용자가 의도한 바와 일치하도록 새로운 image를 생성하도록 하는 것 = 새로운 user-specified concepts에 대한 language-guided generation
이러한 pseudo-word(유사단어)를 찾기 위해 본 논문에서는 task를 하나로 inversion시켜 프레임화함
주어진 pre-trained T2I model 모델과 concept을 나타내는 small(3-5) image set가 주어질 때, 저자들은 “A photo of 𝑆∗”과 같은 형태의 문장을 설정해서 주어진 작은 dataset에서 이미지를 재구성하는 것으로 이어지는 single-word embedding을 찾는 것을 목표로 함
이 embedding은 optimization process를 통해 찾아질 수 있고, 이를 Textual Inversion이라 부름
이때 이 과정에서 생성모델(본 논문에서는 LDM)은 untouched되어 있음(따로 수정이 들어가지 않음) -> 새로운 task에 대한 fine-tuning을 할 때 일반적으로 손실되는 text 이해도나 generalization을 유지할 수 있음
CLIP-based reconstruction에서, 본 논문의 method가 unique detail과 concept을 잘 capture함
context text를 𝑆∗로 대체하여, style transfer 역시 가능
동시에 여러 word를 추론할 수 있지만, 새로운 word간의 관계 추론에는 어려움을 겪음
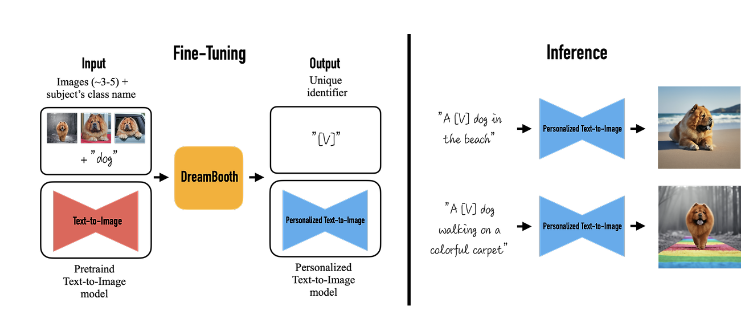
2. Dreambooth
: DreamBooth는 3~5장의 이미지를 이용하여 모델을 fine-tuning하고, 주어진 컨셉을 나타내는 Unique Identifier, 즉 고유 식별자([V])를 사용하여 이미지를 합성함
기존의 모델들 : key visual features에 대한 높은 충실도를 유지하면서 새로운 맥락의 사진을 생성하는 것이 어려움
large T2I 모델들은 대규모의 이미지-캡션 데이터셋에서 학습되었기 때문에, strong semantic prior를 가지고 있기 때문
-> 몇 장의 이미지로 T2I 모델을 fine-tuning 하면서도, 기존 모델의 semantic knowledge를 보존하는 것이 DreamBooth의 목적
DreamBooth는 기존의 fine-tuning과는 달리 적은 수의 이미지만으로 모델의 오염(overfitting, language drift)없이 학습이 가능하기 때문에 개인이 더 손쉽게 fine-tuning이 가능하다는 장점이 존재함
input으로 몇장 이미지와 대상에 대한 class 이름이 주어지며 이를 DreamBooth를 통해 fine-tuning하면, [V]에 대해 학습된 personalized T2I model이 output으로 나오게 되는 것
ex : 이미 여러 동물에 대해 학습된 어떤 pretrained model이 존재할 때, 내가 키우는 개를 학습시키고 싶음 -> 학습 이미지 : 내가 키우는 개 [V] 에 대한 사진, class name : "dog"
dog 말고 더 상위 개념인 animal로 정해도 되지만 너무 포괄적이기에 모든 animal의 특성이 [V]와 섞이게 되어 좋지 못한 결과물이 나올 가능성이 높아질 것
모델은 fine-tuning 과정에서 사용자가 생성하고자 하는특정 subject와 "새로운 단어"(unique identifier)를 함께 학습함
few-shot dataset으로 subject-identifier를 학습하고 아래에서는 기존 모델이 생성한 이미지를 학습하여 사전 지식을 유지함
"A [V] dog" 처럼 unique identifier와 클래스 이름이 합쳐진 텍스트 프롬프트를 사용해서 파인튜닝함
prompt로 "[identifier] [class noun]" 의 형태를 이용
[identifier] : subject를 의미하는 unique identifier
[class noun] : subject의 class를 대략적으로 설명하는 단어. 모델의 사전 지식을 활용하여 훈련 시간을 줄이고 성능을 향상시키는 역할 ex) dog, cat, watch
하지만 이렇게만 학습을 진행하면 language drift 현상 발생 -> 따라서 논문의 저자들은 이를 방지하기 위해서 클래스에 대한 semantic prior를 활용하는 autogenous,class-specific prior preservation loss도 제안
연구진들은 모델의 vocabulary에서 희귀 토큰을 찾아 text space로 변환하는 방식으로 unique token을 선택함
희귀 토큰 𝑓(𝑉^)를 찾고 대응하는 단어𝑉를 unique identifier로 사용함
모델이 단어를 원래의 의미로부터 분리하고 컨셉과 연결되도록 학습해야 함 -> 따라서 특별한 의미를 가지지 않는 단어를 활용하는 것이 효율적임
무작위 알파벳으로 구성된 "xxy5syt00"와 같은 단어는 tokenizer에 의해 각 글자별로 토큰화되기 때문에 마찬가지로 좋지 않은 선택임
기존 모델의 내용을 유지하면서 새로운 것을 학습할 때 DreamBooth는 class image(Regularization image, 정규화 이미지)를 사용함
학습하고 싶은 이미지인 A [V] dog에 대한 input image를 학습하과 동시에 기존 모델이 이용해 출력한 A dog라는 class name에 대한 이미지인 class image를 같이 학습해 기존 모델이 가진 class name에 대한 지식을 잊지 않도록 함
학습에 class-specific prior preservation loss라는 자체적인 손실 함수 이용함
기존 diffusion model의 손실함수와의 차이점은 +뒤의 term이 추가되었다는 것인데, lambda와 class image에 대한 손실함수를 곱하였기 때문에 lambda 값을 조절해 가중치에 어느정도로 class image의 손실함수를 추가할지 조절이 가능
YOLO 이전의 방식들은 2-stage detector라고 하여 첫번째 물체를 인식하고, 두번째 인식된 물체의 이미지 영역을 짤라서 Classification 하는 방식으로 처리를 하였다면, YOLO와 SSD 같은 방법들은 그 과정을 딥러닝 모델에서 단 한 번의 과정을 통해서 처리하도록 함
Abstract
YOLO 연구진은 object detection에 새로운 접근 방식을 적용함
기존의 multi-task 문제를 하나의 regression 문제로 재정의함
이미지 전체에 대해 하나의 신경망이 한 번의 계산만으로 bounding box와 클래스 확률(class probability)를 예측함 = 단일 네트워크가 bounding box와 class probability 예측을 한 번에 수행함
bounding box : 객체의 위치를 알려주기 위해 객체의 둘레를 감싼 직사각형 박스
클래스 확률 : bounding box로 둘러싸인 객체가 어떤 클래스에 해당하는지에 관한 확률
모든 파이프라인이 단일 네트워크 => end-to-end 형식임
YOLO의 통합된 모델은 굉장히 빠름
Localization error는 타 모델에 비해 더 많지만, background에 대한 false positive (배경을 물체로 검출하는 에러)는 더 적음
1. Introduction
사람은 이미지를 보면 어디에 무엇이 있는지를 한 번에 파악할 수 있음. 사람의 시각 체계는 빠르고 정확하기 때문
-> 운전을 하면서도 빠르게 지나가는 바깥 환경을 빠르고 정확하게 인식할 수 있음
기존의 detection 모델은 분류기(classifier)를 재정의해 검출기(detector)로 사용함
분류(classification) : 하나의 이미지를 보고 그것이 개인지 고양이인지 판단하는 것
객체 검출(object detection) : 하나의 이미지 내에서 개는 어디에 위치해 있고, 고양이는 어디에 위치해 있는지 판단하는 것 => 객체 검출은 분류뿐만 아니라 위치 정보도 판단해야 함
기존의 객체 검출 모델로는 DPM과 R-CNN이 있음
DPM(Deformable parts models) : 이미지 전체를 거쳐 sliding window 방식으로 객체 검출을 하는 모델. 전체 이미지를 classifier로 스캔하는 방식 형태의 방법론 사용
sliding window 방식 : 이미지를 격자 또는 창(window)로 나누고, 각 창 내에서 객체의 존재 여부를 확인하고 분류. 객체가 다양한 크기와 위치에 나타날 수 있는 상황에서 유용한 방식. 다양한 크기의 객체 탐지가 가능하며, 작은 객체와 큰 객체 모두 처리할 수 있다는 장점이 존재하나 계산 비용이 높고 연산 부하가 증가할 수 있
R-CNN : 이미지 안에 bounding box를 생성하기 위해 region proposal이라는 방법 사용. 그렇게 제안된 bounding box에 classifier를 적용해 분류함
region proposal / classification / box regression이라는 3가지의 단계를 거치는데, 각 단계를 개별적으로 학습해야 함. (분류 후 bounding box를 조정하고, 중복된 검출을 제거하고, 객체에 따라 box의 점수를 재산정하기 위해 후처리(post-processing) 진행)
이러한 복잡성으로 인해 R-CNN은 느림 & 각 절차를 독립적으로 훈련시켜야 하므로 최적화 힘듦
따라서 YOLO 연구진은 객체 검출을 하나의 회귀 문제(single regression problem)로 보고 절차를 개선함
이미지의 픽셀로부터 bounding box의 위치(coordinates), 클래스 확률(class probabilities)을 구하기까지의 일련의 절차를 하나의 회귀 문제로 재정의한 것
End-to-End 방식의 통합된 구조로 되어 있으며, 이미지를 convolutional neural network에 한 번 평가(inference)하는 것을 통해서 동시에 다수의 bounding box와 class 확률을 구하게 됨
기존의 방법론인 Classification모델을 변형한 방법론에서 벗어나, Object Detection 문제를 regression문제로 정의하여 이미지에서 직접 bounding box 좌표와 각 클래스의 확률을 구하는
=> 이미지 내에 어떤 물체가 있고 그 물체가 어디에 있는지를 하나의 파이프라인으로 빠르게 구해줌
=> 이미지를 한 번만 보면 객체를 검출할 수 있다 하여 YOLO(You Only Look Once)라 명명함
하나의 컨볼루션 네트워크(convolutional network)가 여러 bounding box와 그 bounding box의 클래스 확률을 동시에 계산해줌
YOLO는 이미지 전체를 학습해 곧바로 검출 성능(detection performance)를 최적화함
-> YOLO의 이런 통합된 모델은 기존의 객체 검출 모델에 비해 여러가지 장점이 존재함
YOLO의 장점
1) 속도가 굉장히 빠름
기존의 복잡한 객체 검출 프로세스를 하나의 회귀 문제로 바꿨기 때문. 그리하여 기존의 객체 검출 모델처럼 복잡한 파이프라인이 필요하지 않음. 단순히 테스트 단계에서 새로운 이미지를 YOLO 신경망에 넣어주기만 하면 쉽게 객체 거출을 할 수 있음
YOLO의 기본 네트워크(base network)는 Titan X GPU에서 배치 처리(batch processing) 없이 1초에 45 프레임을 처리하고, 빠른 버전의 YOLO(Fast YOLO)는 1초에 150 프레임을 처리함
이는 동영상을 실시간으로 처리할 수 있다는 의미임 (25밀리 초 이하의 지연시간으로 처리 가능)
YOLO는 다른 실시간 객체 검출 모델보다 2배 이상의 mAP(mean average precision의 약자로 정확성을 뜻함)를 갖습니다
2) YOLO는 예측시 이미지 전체를 봄 -> background error 적음
sliding window나 region proposal 방식이 아닌 convolutional neural network를 사용하는 방식으로 훈련과 테스트 단계에서 이미지 전체를 보기 때문에 클래스의 모양에 대한 정보뿐만 아니라 주변 정보까지 학습해 처리함
YOLO 이전의 객체 검출 모델 중 가장 성능이 좋은 모델인 Fast R-CNN은 주변 정보까지는 처리하지 못했음
그래서 아무 물체가 없는 배경(background)에 반점이나 노이즈가 있으면 그것을 물체로 인식함 = background error
YOLO는 이미지 전체를 처리하기 때문에 background error가 Fast R-CNN에 비해 대략 1/2 가량으로 훨씬 적음
3) YOLO는 물체의 일반화된 Object 표현을 학습함
실험적으로 자연의 dataset을 학습시킨 후 학습시킨 네트워크에 artwork 이미지를 입력했을 때, DPM, R-CNN 대비 많은 격차로 좋은 detection 성능을 보임
단, SOTA 객체 검출 모델에 비해 정확도(mAP)가 다소 떨어짐. 작은 물체에 대해 detection 성능이 떨어짐
2. Unified Detection
YOLO의 핵심 = Unified Detection
YOLO에서 주장하는 Unified Detection의 개념
= 원본 이미지를 입력으로 받은 모델이 object detection에 필요한 모든 연산을 수행할 수 있다는 의미. YOLO는 단일 convolutional neural network 모델 하나로 (object detection 문제를 풀기 위한) 특징 추출, 바운딩 박스 계산, 클래스 분류를 모두 수행함
YOLO는 기존의 모델에는 없었던 다양한 이점들이 존재함
1) 모델이 이미지 전체를 보고 바운딩 박스를 예측할 수 있음
2) Unified Detection이라는 용어 그래도 bounding box regression과 multi-class classification을 동시에 수행할 수 있음
이러한 이점들로 인해 높은 mAP를 유지하면서, end-to-end 학습이 가능하고, 실시간의 inference 속도가 가능함
YOLO는 input images를 S x S 그리드로 나눔
만약 어떤 객체의 중점이 특정 그리드 셀 안에 존재한다면, 해당 그리드 셀이 그 객체를 검출해야 함.
각 그리드 셀은 B개의 바운딩 박스를 예측하고, 각 바운딩박스 마다 confidence scores를 예측함
confidence scores: 해당 바운딩 박스 내에 객체가 존재할 확률을 의미하며 0에서 1 사이의 값을 가짐confidence scores 수식
IOU(Intersection over union) : 객체의 실제 bounding box와 예측 bounding box의 합집합 면적 대비 교집합 면적의 비율. 즉, IOU = (실제 bounding box와 예측 bounding box의 교집합) / (실제 bounding box와 예측 bounding box의 합집합). 예측된 bounding box가 그 클래스(class) 객체에 얼마나 잘 들어맞는지를 의미
만약 그리드 셀 안에 아무 객체가 없으면 Pr(Object) = 0 -> confidence scores = 0
그리드 셀에 어떤 객체가 확실히 있다고 예측했을 때, 즉 Pr(Object)=1일 때가 가장 이상적 -> confidence score가 IOU와 같다면 가장 이상적인 score임
각각의 바운딩 박스는 5개의 예측치(x, y, w, h, confidence)로 구성되어 있음
(x, y) : 바운딩 박스의 중심점. 각 그리드 셀마다 상대적인 값으로 표현됨
절대 위치가 아니라 그리드 셀 내의 상대 위치이므로 0~1 사이의 값 가짐
(x, y)가 정확히 그리드 셀 중앙에 위치한다면 (x, y)=(0.5, 0.5)
(w, h) : 바운딩 박스의 width, height. 전체 이미지에 대해 상대적인 값으로 표현됨
이미지 전체의 너비와 높이를 1이라고 했을 때 bounding box의 너비와 높이가 몇인지를 상대적인 값으로 나타냄. (w, h) 0~1 사이의 값을 가짐
confidence : 앞서 다룬 confidence score
Conditional Class Probabilities (C)
= 그리드 셀 안에 객체가 있다는 조건 하에 그 객체가 어떤 클래스(class)인지에 대한 조건부 확률
각각의 그리드 셀은 conditional class probabilities(C)를 예측함
YOLO에서는 그리드 당 예측하는 바운딩 박스의 갯수(B)와 상관없이 그리드 당 오직 하나의 클래스 확률만 예측함
= 하나의 그리드 셀에서는 클래스 하나만 예측
Class-specific Confidence Score
Test 단계에서는 conditional class probability(C)와 개별 bounding box의 confidence score를 곱해주는데, 이를 각 bounding box에 대한 class-specific confidence score라 부름
해당 바운딩 박스에서 특정 클래스 객체가 나타날 확률(Pr(Class_i)과 객체에 맞게 바운딩 박스를 올바르게 예측했는지(IOU_pred^truth)를 나타냄
논문에서는 PASCAL VOC를 이용하여 Evaluation을 진행함 (S = 7, B = 2, C = 20 으로 설정)
(PASCAL VOC에는 20개의 레이블 존재하기에 C = 20)
S = 7 -> input image는 7*7 그리드로 나뉨
B = 2 -> 하나의 그리드 셀에서 2개의 bounding box를 예측하겠다는 의미
-> 따라서 모델의 최종 output tensor의 dimension은 7 x 7 x 30
fully connected layers는 추출된 특징을 기반으로 클래스 확률과 바운딩 박스의 좌표를 추론함
YOLO의 신경망 구조는 이미지 분류에 사용되는 GoogLeNet에서 따왔으며, 24개의 convolutional layers와 2개의 fully connected layers로 구성됨
GoogLeNet의 인셉션 구조 대신 YOLO는 1 x 1 축소 계층(reduction layer)과 3 x 3 컨볼루션 계층의 결합을 사용함
1 x 1 축소 계층(reduction layer)과 3 x 3 컨볼루션 계층의 결합이 인셉션 구조를 대신함
모델의 최종 아웃풋은 7 x 7 x 30의 예측 텐서(prediction tensors)임
FastYOLO : 좀 더 빠른 객체 인식 속도를 위해 YOLO보다 더 적은 convolutional layer(24개 대신 9개)과 필터를 사용. 크기만 다를 뿐이고 훈련 및 테스트 시 사용하는 나머지 파라미터는 YOLO와 모두 동일함
2.2 Training
YOLO의 학습 과정은 아래와 같음
2.2.1 Pretraining Network
YOLO 모델의 convolutional layers는 ImageNet Dataset으로 Pretrain함
24개의 convolutional layers 중 앞단의 20개의 convolutional layers를 pretrain하고 이어서 fully connected layer를 연결함
20개의 convolutional layers 뒷단에 average-pooling layer와 fully connected layer를 붙여서 ImageNet의 1000개의 class를 분류하는 네트워크를 만들고 이를 학습시킴
논문 기준 1주일간 학습 후 ImageNet 2012 validation set 기준 top-5 accuracy 88%
ImageNet은 분류(classification)를 위한 데이터 셋이라 사전 훈련된 분류 모델을 객체 검출(object detection) 모델로 바꾸어야 함
연구진은 사전 훈련된 앞단 20개의 pretrained convolutional layer 뒤에 4개의 convolutional layer 및 2개의 fully connected layer을 추가하여 성능을 향상시켰음
4개의 컨볼루션 계층 및 2개의 전결합 계층을 추가할 때, 이 계층의 가중치(weights)는 임의로 초기화함
또한, 객체 검출을 위해서는 이미지 정보의 해상도가 높아야 하기에 입력 이미지의 해상도를 224 x 224에서 448 x 448로 증가시킴
2.2.2 Normalized Bounding Boxes
이 신경망의 최종 아웃풋(예측값) = 클래스 확률(class probabilities) & bounding box 위치정보(coordinates)
bounding box의 위치정보에는 bounding box의 너비(width)와 높이(height)와 bounding box의 중심 좌표(x, y)가 존재하는데, YOLO 연구진은 너비, 높이, 중심 좌표값(w, h, x, y)을 모두 0~1 사이의 값으로 정규화(normalize)함
바운딩 박스의 width와 height는 각각 이미지의 width와 height로 정규화시킴 -> 0에서 1 사이의 값
바운딩 박스의 중심 좌표인 x와 y는 특정 그리드 셀에서의 offset으로 나타냄 -> 0에서 1 사이의 값
2.2.3 Nolinearity
YOLO 신경망의 마지막 계층에는 선형 활성화 함수(linear activation function)을 사용하고, 나머지 모든 계층에는 leaky ReLU를 적용함
ReLU는 0 이하의 값은 모두 0
leaky ReLU는 0 이하의 값도 작은 음수 값을 가짐
2.2.4 고려해야 할 사항들
1) SSE의 문제
YOLO의 loss는 SSE(sum-squared error)를 기반으로 함 -> 최종 아웃풋의 SSE(sum-squared error)를 최적화(optimize) 해야 함
SSE를 사용한 이유 : SSE가 최적화하기 쉽기 때문
하지만 SSE를 최적화하는 것이 YOLO의 최종 목적인 mAP(평균 정확도)를 높이는 것과 완벽하게 일치하지는 않음
YOLO의 loss에는 bounding box의 위치를 얼마나 잘 예측했는지에 대한 loss인 localization loss와 클래스를 얼마나 잘 예측했는지에 대한 loss인 classification loss가 존재하는데, localization loss와 classification loss의 가중치를 동일하게 두고 학습시키는 것은 좋은 방법이 아님
하지만 SSE를 최적화하는 방식은 이 두 loss의 가중치를 동일하게 취급함
또한 SSE를 사용하면 바운딩 박스가 큰 객체와 작은 객체에 동일한 가중치를 줄 때도 문제가 생길 수 있음
작은 bounding box가 큰 bounding box보다 작은 위치 변화에 더 민감하기 때문
큰 객체를 둘러싸는 bounding box는 조금 움직여도 여전히 큰 객체를 잘 감싸지만, 작은 객체를 둘러싸는 bounding box는 조금만 움직여도 작은 객체를 벗어나게 됨
-> 이를 개선하기 위해 bounding box의 너비(widht)와 높이(hegith)에 square root를 취해줌.
너비와 높이에 square root를 취해주면 너비와 높이가 커짐에 따라 그 증가율이 감소해 loss에 대한 가중치를 감소시키는 효과가 있기 때문
2) λ_coord와 λ_noobj로 가중치 조절
또 다른 문제로는 이미지 내 대부분의 그리드 셀에는 객체가 없다는 것임(배경 영역이 전경 영역보다 더 크기 때문)
그리드 셀에 객체가 없다면 confidence score=0 -> 대부분의 그리드 셀의 confidence socre=0이 되도록 학습할 수밖에 없는데, 이는 모델의 불균형을 초래함
-> YOLO는 이를 개선하기 위해 객체가 존재하는 bounding box 좌표(coordinate)에 대한 loss의 가중치를 증가시키고, 객체가 존재하지 않는 bounding box의 confidence loss에 대한 가중치는 감소시킴
= localization loss와 classification loss 중 localization loss의 가중치를 증가시키고, 객체가 없는 그리드 셀의 confidence loss보다 객체가 존재하는 그리드 셀의 confidence loss의 가중치를 증가시킨다는 뜻
이를 위해 λ_coord와 λ_noobj라는 두 가지의 파라미터 사용함 (논문에서는 λ_coord=5, λ_noobj=0.5로 가중치를 줌)
2.2.5 Multiple bounding boxes per gridcell
YOLO는 하나의 그리드 셀 당 여러 개의 bounding box를 예측함
훈련(training) 단계에서는 객체 하나당 하나의 바운딩 박스와 매칭시켜야 하므로, 여러 개의 바운딩 박스 중 하나를 선택해야 함
-> 따라서 여러 개의 bounding box 중 하나만 선택해야 함
이를 위해 예측된 여러 bounding box 중 실제 객체를 감싸는 ground-truth boudning box와의 IOU가 가장 큰 것을 선택함
ground-truth boudning box와의 IOU가 가장 크다 = 객체를 가장 잘 감싼다
이렇게 훈련된 bounding box predictor는 특정 크기(size), 종횡비(aspect ratios), 객체의 클래스(classes of object)를 잘 예측해 overall recall을 상승시킬 수 있음
2.2.6 Loss function
훈련 단계에서 사용하는 loss function은 다음과 같음
1_obj^i : i번째 그리드 셀 에 있는 j번째 바운딩박스에 객체가 존재하는지 여부
1_obj^i = 1인 바운딩 박스는 해당 객체를 검출해 내야 함
1_ij^obj는 그리드 셀 i의 j번째 bounding box predictor가 사용되는지 여부
수식의 classification loss의 경우에는 1_obj^i = 1인 바운딩 박스에만 적용이 되는 loss임(이는 Pr(Class_i|Object)를 반영한 결과).
또한 borunding box coordinate loss의 경우에도 위와 마찬가지임
위 loss function의 5개 식은 차례대로 아래와 같은 의미를 가짐
1) Object가 존재하는 그리드 셀 i의 bounding box predictor j에 대해, x와 y의 loss를 계산. 2) Object가 존재하는 그리드 셀 i의 bounding box predictor j에 대해, w와 h의 loss를 계산.
큰 box에 대해서는 작은 분산(small deviation)을 반영하기 위해 제곱근을 취한 후, sum-squared error를 구함 (같은 error라도 큰 box의 경우 상대적으로 IOU에 영향을 적게 줌)
3) Object가 존재하는 그리드 셀 i의 bounding box predictor j에 대해, confidence score의 loss를 계산. (Ci = 1) 4) Object가 존재하지 않는 그리드 셀 i의 bounding box predictor j에 대해, confidence score의 loss를 계산. (Ci = 0) 5) Object가 존재하는 그리드 셀 i에 대해, conditional class probability의 loss를 계산. (p_i(c)=1 if class c is correct, otherwise: p_i(c)=0)
2.2.7 학습 및 하이퍼 파라미터
PASCAL VOC 2007 / 2012를 이용해서 총 135 epochs를 학습시킴
하이퍼 파라미터 세팅은 아래와 같음
batch size = 64
momentum of 0.9
decay = 0.0005
초반에는 학습률(learning rate)을 0.001에서 0.01로 천천히 상승시킴
처음부터 높은 learning rate로 훈련시켰다면 기울기 폭발(gradient explosion)이 발생하기 때문
이후 75 epoch 동안에는 0.01, 30 epoch 동안에는 0.001, 그리고 마지막 30 epoch 동안은 0.0001로 learning rate를 설정함
learning rate를 처음에는 점점 증가시켰다가 다시 감소시킴
YOLO에서는 오버피팅을 방지하기 위해 dropout과 data augmentation 기법을 사용함
dropout : 첫 번째 fully connected layer에 붙으며 dropout rate = 0.5로 설정
Data augmentation : scaling, translation, exposure, saturation을 조절하는 방식으로 다양하게 진행하며, 원본 이미지의 20%까지 랜덤 스케일링(random scaling)과 랜덤 이동(random translation)을 적용함
2.3 추론(Inference)
훈련 단계와 마찬가지로, 추론 단계에서도 테스트 이미지로부터 객체를 검출하는 데에는 하나의 신경망 계산만 하면 됨
파스칼 VOC 데이터 셋에 대해서 YOLO는 한 이미지 당 98개의 bounding box를 예측해주고, 그 bounding box마다 클래스 확률(class probabilities)을 구해줌
R-CNN 등과 다르게 하나의 신경망 계산(a single network evaluation)만 필요하기 때문에 입력 이미지를 네트워크에 단 한 번만 통과시키면 되므로 속도가 굉장히 빠름
YOLO의 그리드 디자인의 단점 : 다중 검출(multiple detections) 문제
: 하나의 객체를 여러 그리드 셀이 동시에 검출하는 경우가 존재함
객체가 그리드셀들의 경계에 위치하거나 여러 그리드 셀을 포함할 만큼 큰 객체인 경우 그 객체에 대한 bounding box가 여러 개 생길 수 있음
= 하나의 그리드 셀이 아닌 여러 그리드 셀에서 해당 객체에 대한 bounding box를 예측할 수 있다는 뜻
-> 비 최대억제(Non-maximal suppression) 로 다중 검출 문제 개선 가능 (YOLO는 NMS를 통해 mAP를 2-3% 가량 올릴 수 있었음)
2.4 YOLO의 한계
1) 공간적 제약(spatial constraints)
YOLO는 하나의 그리드 셀마다 두 개의 bounding box를 예측 & 하나의 그리드 셀마다 오직 하나의 객체만 검출할 수 있음
-> 공간적 제약(spatial constraints)을 야기
공간적 제약: 하나의 그리드 셀은 오직 하나의 객체만 검출하므로 하나의 그리드 셀에 두 개 이상의 객체가 붙어있다면 이를 잘 검출하지 못하는 문제
ex) 새 떼와 같이 작은 물체가 몰려있는 경우 객체 검출이 제한적일 수 밖에 없음(오직 하나의 객체만 검출하는데 여러 객체가 몰려있으면 검출하지 못하는 객체도 존재)
2) 훈련 단계에서 학습하지 못한 종횡비(aspect ratio, 가로 세로 비율)를 테스트 단계에서 마주하면 고전함
바운딩 박스를 데이터로부터 학습하기 때문에 일반화 능력이 떨어지고, 이로 인해 train 단계에서 보지 못했던 종횡비의 객체를 잘 검출하지 못함
3) 부정확한 localization 문제
YOLO 모델은 큰 bounding box와 작은 bounding box의 loss에 대해 동일한 가중치를 둔다는 단점이 존재함
-> 크기가 큰 bounding box는 위치가 약간 달라져도 비교적 성능에 별 영향을 주지 않는데, 크기가 작은 bounding box는 위치가 조금만 달라져도 성능에 큰 영향을 줄 수 있음
큰 bounding box에 비해 작은 bounding box가 위치 변화에 따른 IOU 변화가 더 심하기 때문
2021년 마이크로소프트에서 제시한 PEFT(parameter-efficient fine-tuning) 기법인 LoRA를 제안한 논문!
원래 우리가 업데이트해야 할 모델의 파라미터 행렬 크기가 3 by 3이라고 하면, full-fine tuning을 진행할 경우 3 by 3 matrix의 모든 값을 계산해야 한다.
하지만 LoRA 기법을 이용하면 3 by 3 matrix를 3 by R(Rank) matrix와 R(Rank) by 3 matrix로 나누어 두 행렬을 각각 업데이트 한다.
그 후 업데이트가 완료된 두 행렬을 곱해줘 3 by 3 matrix로 크기를 복구해준다.
여기서 R(Rank)의 값을 우리가 임의로 정해줘 랭크를 얼마나 반영해 업데이트 할 지 정해줄 수 있다.
즉, 기존의 pre-trained layer의 가중치는 고정을 한 채, 새로운 레이어의 가중치만을 학습시키는 것이다.
이렇게 하면 full fine-tuning 대비 아주 적은 양의 파라미터만 훈련시키면서, full Fine-tuning과 같거나 심지어 더 좋은 성능을 내기도 한다고 한다.
BERT, RoBERTa와 같이 그렇게 크지 않은 모델을 사용할 때는 굳이 LoRA를 사용하지 않고 full fine- tuning을 진행했으나, Llama 등의 모델이 나오며 이 모델들을 full fine-tuning 하기에는 컴퓨팅 소스가 매우 크기 때문에 LoRA를 사용한다.
기존 LLM 모델은 RAM에 저장하고, CPU inference만 진행하고, LoRA 가중치는 GPU에 저장해 학습을 진행한다.
Abstract
LoRA는 GPT와 같은 LLM을 특정 task에 fine-tuning(adaptation)하는 데 있어서 time과 resource 비용이 너무 크다는 단점을 해결하기 위한 방법으로 제시됨
pre-trained model의 weight를 freeze한 뒤 Transformer 아키텍처의 layers에 훈련 가능 rank decomposition matrices을 inject하여 downstream tasks의 훈련가능한 parameters를 줄일 수 있음
GPT-3와 비교하여 LoRA는 훈련 가능한 parameters를 약 10,000배 줄일 수 있었음 & GPU 메모리 요구량 3배 줄이기 가능
LoRA는 다양한 모델에서 기존 혹은 그 이상의 성능을 보여줌
기존 adapters의 inference latency 문제가 LoRA에는 적용되지 않음
1. Introduction
pretrained language model은 모델의 모든 파라미터를 업데이트 하는 finetuning 방법을 통해 다양한 task에 적용되어 왔음
하지만 정작 업데이트에 사용되는 파라미터는 극히 일부이기 때문에 비효율적으로 자원을 사용하게 됨
ex) GPT-2, RoBERTa large model의 경우 fine-tuning만 몇 달이 걸림
이에 downstream task를 위해 external module을 학습 or 몇몇 파라미터만 adapt하는 방식이 제안되어 왔으며, 각가의 task를 수행하기 위한 pretrained model에 적은 양의 task-specific parameter를 저장하고 로드하는 것이 제안되어 왔음
하지만 이러한 방식도 inference latency가 유도됨 or 모델의 입력 가능한 문장 길이 줄여야함(trade off 고려)
-> Low-Rank Adapation(LoRA)를 제안
downstream task : 사전 학습된 모델을 사용하여 특정 작업을 수행하는 것을 의미. 즉, 사전 학습(pre-training)된 모델의 가중치를 고정(frozen)한 상태에서, 저차원 매트릭스(LoRA의 (A)와 (B))를 학습하여 특정 작업에 맞게 모델을 조정하는 것
LoRA
LoRA는 low "intrinsic rank"의 weight를 학습하는 것
pre-trained된 weight를 고정시키는 대신, dense layers의 rank decomposition matrices를 optimization함으로써 기존 dense layers를 간접적으로 학습시
Low-Rank 방법의 motivation : "over-parameterized model은 low intrinsic dimension으로 존재하고 있다"는 사실 -> model adaptation 동안 weight의 변화도 low intrinsic rank를 가질 거라고 가정
Low-rank decomposition된 weights는 기존의 W보다 훨씬 작은 크기의 weight이기 때문에 time과 resource cost를 줄일 수 있음
또한 pretrained model을 가지고 있는 상태에서 특정 task에 adaptation하기 위해 A와 B만 storage에 저장하면 되고 다른 task에 adaptation하기 위해 또 다른 A', B'만 갈아 끼우면 되므로 storage, task switching면에서도 효율적임
adaptation : 사전 학습된 모델을 특정 작업에 맞게 조정하는 과정
inference시에도 fine-tuned model의 latency 성능이 낮아지지도 않음
LoRA의 advantages
1) Trainable 파라미터의 개수가 크게 줄어드므로 줄어든 비율만큼 checkpoint 저장 공간의 줄어든게 됨
checkpoint는 frozen 파라미터는 저장하지 않고 오직 trainable 파라미터만 저장하기 때문임
2) 작은 low-rank matrices만을 optimize함
-> 학습 효과적으로 할 수 있음 & 요구되는 하드웨어 성능도 줄이기 가능
adaptation 옵티마이저를 사용해서 대부분의 매개변수에 대한 옵티마이저 상태를 유지하거나 그래디언트를 계산할 필요가 없기 때문
Trainable 파라미터의 개수가 크게 줄어드므로 fine-tuning 시 필요한 GPU 메모리 공간이 줄어든게 (fine-tuning 시 학습을 위해 필요한 추가적인 메모리 공간은 trainable 파라미터의 개수에 의존하므로)
3) Adaptation module(gradient=BA) 가 그대로 본래 weight에 더해지는 심플한 선형 구조로 inference latency가 없음
inference latency : input이 들어가서 모델이 예측을 하기까지 걸리는 시간
4) 기존의 모델 등에 다양하게 적용 가능함
downstream task에 맞춰 학습된 BA를 손쉽게 교체할 수 있음
Terminologies and Conventions
𝑑_model : transformer 구조 상의 입력과 출력 차원 크기
𝑊𝑞: 쿼리 행렬
𝑊𝑘: 키 행렬
𝑊𝑣: 값 행렬
𝑊𝑜: 출력 행렬
𝑊 또는 𝑊_0 : pre-trained된 weight 행렬
Δ𝑊 : adaptation 동안의 가중치 변화의 총량(accumulated gradient update)
각 downstream task는 context-target pair의 training dataset Z = {(x_i, y_i)}_i = 1,...,N 을 가짐
2) fine-tuning 과정에서 LLM이 튜닝되는 Φ가 최적화되는 식은 아래와 같음
equation 1
기존의 full fine-tuning이라면 모델은 pre-trained weights Φ_0으로 initialized될 것이고, 위와 같은 conditional language modeling objective를 minimize하기 위해 Φ_0 + ΔΦ를 update 함
직관적으로 backpropagation할 때의 모델을 나타내면, Φ = Φ_0 + ΔΦ가 됨
위의 full fine-tuning을 사용할 경우 각 down stream task를 위해 | Φ_0 | dimension과 같은 크기의 | ΔΦ |를 매번 재학습해야 한다는 문제점을 가짐
-> LoRA는 update해야하는 파라미터를 ΔΦ = ΔΦ(Θ)와 같이 encode해 훨씬 작은 size의 파라미터 Θ로 대체 학습함 (|Θ| << |Φ_0|)
-> 최적의 ΔΦ를 찾는 task는 Θ를 optimization하는 것으로 대체됨
3) equation 1에 근거해 만약 accumulated gradient values( ΔΦ)를 기존보다 훨씬 적은 파라미터인 Θ로 치환하여 ΔΦ(Θ)로 나타내면 아래와 같이 바뀌게 됨
위와 같은 LoRA 방식으로 GPT-3을 fine-tuning할 경우 기존 full fine-tuning보다 학습해야 할 파라미터 수가 전체의 0.01%로 줄어들게 됨
3. Aren't Existing Solutions Good Enough?
기존의 방법론들은 large-scale과 latency에 민감한 production들에 한계가 존재했음
1) Adapter Layers Introduce Inference Latency
어댑터 레이어는 추가 연산을 필요로 하므로 지연 시간을 피할 수 없는 구조임
대형 신경망 모델에는 하드웨어 병렬화를 사용해 지연 시간을 줄이는 반면, adapter layer는 순차적으로 처리되어야 함 -> 어댑터를 사용할 때 latency가 존재
2) Directly Optimizing the Prompt is Hard Prefix Tuning은 학습이 어려우며, 학습 가능한 파라미터의 변화가 항상 일정하지 않다는 점에서 최적화가 쉽지 않음
3) single pair of garment and person images를 사용해 모델을 커스터마이징하는 방법을 제안함 -> 이미지의 시각적 품질 향상(특히 wild scenario에서)
4) 의류 이미지에 대한 상세한 캡션 제공 -> T2I diffusion model의 prior knowledge를 유지하는 것의 중요성을 보임
상세한 캡션(예: 소매 길이, 목선 모양, 아이템 종류 등). 모델이 더 정확하고 자연스러운 이미지를 생성하는 데 기여함.
Method
1. Backgrounds on Diffusion Models
Diffusion models
: 데이터에 Gaussian noise를 점진적으로 추가하는 forward process & 무작위로 noise를 점진적으로 제거해 샘플을 생성하는 reverse process로 구성되는 generative model
- x_0 : data point (예: image or output of autoencoder인 latent)
- noise schedules
- forward process
이때 충분히 큰 sigma_t와 x_t는 pure random Gaussian noise와 다르지 않다.
- reverse process
: data distribution에 따라 x_t에서 initialized되고 x_t에서 x_0로 denoise된다.
Text-to-image (T2I) diffusion models
: pretrained text encoder (ex: T5, CLIP text encoder)를 사용해 임베딩으로 인코딩된 텍스트에 조건부 이미지의 분포를 모델링하는 diffusion model
- diffusion model을 위해 convolutional UNet이 개발되었지만, 최근 연구에서는 UNet을 위해 transformer architectures를 융합할 수 있다는 가능성을 보여줌
- diffusion model의 training은 perturbed data distribution의 score function과 동등(equivalent)한 것으로 나타났는데, 이는 ϵ-noise prediction loss으로 드러남
- data x_0와 text embedding c가 주어졌을 때, T2I diffusion model의 training loss
classifier-free guidance (CFG) 사용 <- unconditional과 conditional 함께 학습
- training 단계에서 text conditioning은 무작위로 dropped out되고(=input에 null-text를 제공), inference 단계에서 CFG는 조건부 및 무조건 noise output을 보간해 text conditioning의 강도를 제어함
Image prompt adapter
본 논문에서는 reference image로 T2I diffusion model을 conditioning하기 위해 image encoder(예: CLIP image encoder)에서 추출한 feature를 활용하고 text conditioning에 추가적인 cross-attention layer를 attach하는 image prompt adapter (IP-Adapter)를 제안함
=> GarmentNet이라는 추가 UNet 인코더로 추출된 low-level feature들은 TryonNet의 self-attention layer에서 융합되고, cross-attention layer를 통해 IP-Adapter의 feature들과 함께 처리됨
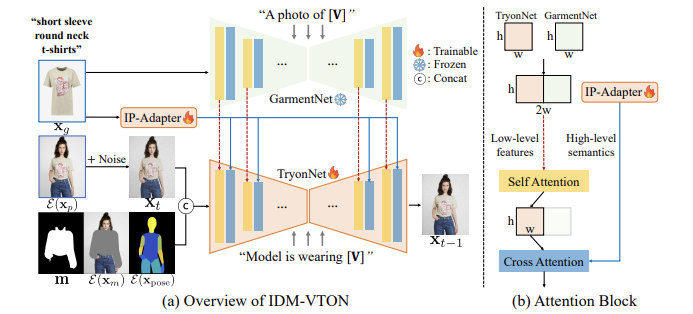
Overview of IDM-VTON
(a) Overview of IDM-VTON
x_p를 처리하는 메인 UNet인 TryonNet, x_g의 high-level semantics를 인코딩하는 IP-Adapter, x_g의 low-level features를 인코딩하는 GarmentNet으로 구성돼있음.
1) UNet에 대한 input으로 noised latent x_t를 segmentation mask m, masked image, densepose와 연결함
의상에 대한 자세한 캡션(위의 [V]) 제공 (예: [V]: “short sleeve round neck t-shirts”)
2) 그 후 GarmentNet(예: “a photo of [V]”)과 TryonNet(예: "Model is wearing [V]”)의 입력 프롬프트에 사용됨
GarmentNet 입력 프롬프트: "A photo of [V]"
TryonNet 입력 프롬프트: "Model is wearing [V]"
(b) Attention Block
1) TryonNet과 GarmentNet의 중간 피처를 연결하여 self-attention layer로 전달하고 output으로 나온 전반부(주로 TryonNet의 피처를 포함함. fist half) 피처를 IP-Adatper의 input으로 사용함
TryonNet의 중간 피처 : 주로 인체의 모양과 포즈 정보 포함
GarmentNet의 중간 피처 : 의상의 low-level detail(예: 텍스처, 패턴)을 포함
연결된 중간 피처는 사람 이미지와 의상 이미지 정보를 모두 포함함
2) cross-attention layer를 통해 text encoder과 IP-Adapter의 피처와 output을 융합함
IP-Adatper는 텍스트 인코더와 CLIP 이미지 인코더로부터 추출된 high-level semantics를 결합해 최종 피처를 생성함. high-level semantics과 low-level features를 효과적으로 융합함. 의류 이미지의 고수준 의미론적 특성을 추출하고 이를 모델에 융합하는 역할을 함
TryonNet과 IP-Adapter 모듈을 finetuning하고 다른 components는 freeze시킴
1. 저차원 manifold 문제에서 score가 정의되고, score matching이 가능하도록 다양한 종류의 gaussian noise를 데이터 분포에 추가함으로써 데이터 분포의 gradient를 통한 score matching이 가능하게 한다.
generative model을 구현하는데 있어 데이터 분포의 gradient를 근사하는 score function을 학습시키고, Langevin dynamics에서의 MCMC sampling을 활용
2. 모든 level의 noise를 추가한 데이터 분포의 gradient를 활용해 score network를 학습시킨 후 annealed Langevin dynamics를 통해 데이터를 sampling한다.
sampling 과정에서 활용되는 brownian motion의 hyperparameter인 gaussian distribution의 variance를 고정하는 것이 아니라 geometric sequence를 이루는 순열을 사용해 annealing하는 방법을 사용함
이 방법론은 DDPM과 같은 프레임워크(SDE)에서 설명되어, score-based diffusion을 구성하는 한 축이 된다.
DDPM, NCSN 후 DDIM이 나왔다고 보면 된다고 함
Introduction
기존의 Generative Model은 크게 두 가지로 나뉜다.
1. Likelihood-based models(우도 기반 모델) - normalizing flow models, VAE 등
PDF(확률밀도함수)를 직접 학습함. PDF를 정의하고 해당 PDF의 likelihood를 최대화하는 방법
데이터의 distribution 자체를 모델링(데이터의 PDF 자체를 모델링해서 그 PDF로부터 sampling하면 생성이 되는 것)
한계 : 확률의 직접적인 계산이 가능하도록 하기 위해 tractable normaling constant가 보장되어야해서 아키텍처에 대한 제약이 있으며, 실제 데이터의 분포를 모르기 때문에 surrogate objectives(대리 목표)에 의존함
2. Implicit generative models(암시적 생성 모델) - GAN
직접적으로 PDF를 모델링하지 않고, Sampling process의 model에 의해 확률 분포를 암시적으로 표현함
한계 : 모드 붕괴 등의 문제가 있는 불안정한 적대적 학습 기법에 의존함 -> 학습 불안정 or 성능 떨어짐
이러한 문제를 해결하기 위해 Score-based Generative model은 Score matching과 Langevin Dynamics를 활용한다.
Score matching으로 훈련된 신경망을 사용해 데이터에서 vector field를 학습하고, Langevin dynamics를 사용해 sample을 생성한다.
하지만 이러한 방법도 문제점이 존재한다.
1. 실제 세계에서의 데이터 세트가 그러하듯, 데이터 분포가 low dimensional manifold에 존재한다면 score는 ambient space에서 정의되지 않고 score matching도 일관된 score 추정치를 제공하는 데 실패한다.
score는 데이터 분포의 log gradient라고 생각하면 된다.
2. low data density 영역에서의 훈련 데이터의 희소성(ex: manifold로부터 멀어진 경우)는 score estimation의 정확도를 방해하고 Langevin dynamics sampling의 mixing을 느리게 한다.
그래서 이 문제들을 해결하기 위해 위 논문에서는
1. 다양한 크기의 random Gaussian noise를 data에perturb한다.
random noise를 주입함으로 결과 분포가 low dimension manifold에 국한되지 않게 한다.
noise의 수준이 크면 원래(unperturbed) 데이터 분포의 low density 영역에 샘플이 생성되어 score estimation이 개선된다.
결정적으로 모든 noise level로 조건화된 단일 score network를 학습하고 모든 noise 크기에 대해 score를 추정한다.
2. annealed version of Langevin dynamics를 제안한다.
처음에는 가장 높은 noise level에 해당하는 score를 사용하고, 점차적으로 원래 데이터 분포와 구별할 수 없을 정도로 작아질 때까지 noise level을 낮추는 an annealed version Langevin dynamics를 제안한다.
이를 통해 제안한 objective는 score network의 모든 파라미터가 tractable하고 어떠한 구조적 제약을 받지 않도록 한다.
또한 다른 모델들과의 정량적 비교도 가능하다.
Score-based generative modeling(SBGM)
score-based generative modeling의 framework의 두 가지 요소로는 Score-matching, Langevin dynamics가 존재한다.
Score
: log-likelihood에 관한 1차 미분
이 논문에서는 data density p(x)에 대한 log likelihood의 미분 의미
s_θ(x)로 표현함
파라미터가 아닌 입력 데이터 x에 대한 미분임
입력 데이터와 score의 input dimension은 동일해야 함
[논문 Summary] NCSN (2019 NIPS) "Generative Modeling by Estimating Gradients of the data distribution" (tistory.com)
D : a neural network parameterized by θ, which will be trained to approximate the score of p_data(x).
generative modeling의 목표 : 데이터 세트를 사용해 p_data(x)에서 새로운 samples를 생성하기 위한 모델을 학습하는 것
만약 PDF가 아래와 같은 형태로 정의된다고 할 때, normalizing constant Z는 복잡한 적분을 통해서 구해야 하기 때문에 계산이 쉽지 않다.
θ로 parameterize된 energy based model
하지만 score function을 이용해 log-likelihood를 계산한다고 하면, log-likelihood에 대해 미분을 취하기 때문에 아래 식과 같이 input에 independent한 normalizing constant 부분이 날아가고 계산이 더 쉬워진다.
score network
논문에서는 Denoising score matching을 이용해 score network를 학습한다.
input : 데이터(x˜) / output: 데이터의 score
+)
데이터 생성을 모집단에서부터 sampling되는 것이라고 봤을 때, 모집단(MNIST)에서 sampling된 데이터들을 관측해서 분석을 진행하는 것.
모집단에서 sampling된 데이터 = 데이터 분포에서 높은 확률값을 갖는 위치에 있는 데이터
해당 데이터들이 높은 확률값을 갖기 때문에 sampling을 진행함에 있어서 자주 sampling이 되고 우리가 해당 데이터들을 관측하게 되는 것임
Score-based generative model의 기본적인 아이디어
간단한 score-based generative model
1. 데이터 공간 상에서 random한 noise 생성
2. Score function(log PDF의 미분(gradient)) 계산
데이터 분포의 PDF를 알고 있다고 가정함!
score function은 데이터가 존재할 확률이 높은 방향을 가리킴
3. 초기 노이즈 상태에서 score function을 이용해 확률 값이 높아지는 방향으로 데이터를 점진적으로 업데이트 -> 데이터 포인트가 점점 실제 데이터 분포에서 높은 확률 밀도를 가지는 영역으로 이동함
4. 업데이트 과정을 반복하면 초기 조이즈는 점차 샘플링된 데이터 와 유사한 데이터 생성 가능
= random한 noise가 실제 데이터와 유사한 샘플로 변환됨 => 우리가 원하는 데이터를 생성하는 것이 가능해지는 것
Score matching for score estimation
Score matching : score function을 학습함으로써 실제 PDF를 구하는 것이 아닌, score 값을 활용해 PDF를 추정하는 것을 의미한다. 데이터 분포의 log 확률 밀도의 경사를 학습해 해당 분포를 모델링하는 방법이다.
목표 : 주어진 데이터 x에 대한 score 값을 계산해주는 모델(Score Network)을 만드는 것
원리 : 데이터 분포의 score 함수와 모델의 score 함수를 일치시키는 것
증명
score matching은 다음과 같은 목표함수를 최소화하여 달성된다.
Score matching을 사용하면 먼저 p_data(x)를 추정하는 모델을 훈련하지 않고도 score network s_θ(x)를 직접 훈련해 ∇x log p_data(x)를 추정할 수 있다.
아래의 식에서 true data distribution의 score function(빨간색)과 estimate한 score function(파란색)간의 fisher divergence를 최소화해야 한다. (min Loss가 목표)
fisher divergence : 두 확률 밀도 함수 p(x)와 q(x) 사이의 차이를 측정하는 방법
score matching의 목표 함수(loss)
하지만 실제 data distribution(빨간색)을 알지 못하기 때문에 직접적으로 위 함수를 최소화하는 것은 불가능하다.
그래서 대신 부분 적분을 활용한 대리 손실 함수를 사용해 score matching을 진행한다.
대리 손실 함수 사용한 버
하지만 trace를 계산하는 과정에서 매우 큰 연산량이 요구된다는 단점이 존재한다.
score matching의 objective에 있는 trace를 계산하고 학습을 진행하려면 항상 dimension의 개수만큼 backpropagation을 진행해야한다는 문제점이 존재함 (계산 복잡) → 이미지와 같이 높은 dimension을 지니는 데이터에 score matching을 적용하는 것이 현실적으로 불가능해짐
1024 X 1024 해상도의 이미지라면 총 1024번의 backpropagation을 수행해야 trace를 구할 수 있음
그래서 trace 연산을 효율적으로 수행하기 위한 방법으로 large scale score matching에 아래의 두 가지 방법을 사용한다.
1. Denoising score matching
데이터 x를 입력받았을 때 x에 약간의 Gaussian noise를 추가한 x˜의 score를 예측한다.
추가한 noise가 충분히 작으면 perturbated data distribution의 score가 원래 데이터의 score와 거의 같아서 원래 데이터의 score를 예측할 수 있다는 원리이다.
주어진 데이터의 분포에 대한 score를 직접 구하는 것이 아니라, 데이터에 주어진 noise에 대한 score를 구하는 것으로 문제를 변환한다. data point에 noise를 줘서 perturb(동요) 시키고 그 noise를 제거하는 방식으로 학습을 진행한다.
trace 부분을 대체하는데 아래의 distribution을 이용한다.
사전 정의된 noise distribution :
noise perturbed data distribution :
→ 즉, 어떤 데이터 x가 주어졌을 때, 이것의 perturbed 데이터인 x˜의 분포를 학습하는 것
이때 위의 distribution을 바탕으로 objective function을 아래와 같이 수정해 모델을 학습할 수 있다.
즉, denoising score matching에서는 주어진 데이터의 분포에 대한 score를 직접 구하는 것이 아니라, 데이터에 주어진 noise에 대한 score를 구하는 것으로 문제를 변환하는 것!
2. Sliced score matching
random projection을 사용해 score matching의 tr(∇xsθ(x))의 근사치를 구한다.
p_v : 다변량 표준 정규분포와 같은 random vector의 simple distribution
random projection의 과정: 무작위로 방향 벡터 v 선택 → 방향으로 projection 진행 → 그 point에 대해 score 계산
Denoising score matching과 달리 original의 unperturbed data distribution에 대한 score 추정값을 제공한다. 하지만 forward mode auto-differentiation으로 인해 4배 더 많은 계산을 필요로 한다.
Sampling with Langevin dynamics - sampling
Langevin dynamics를 통해 score function log p_data(x)만을 사용해 PDF p(x)로부터 샘플을 생성할 수 있다.
앞의 과정들을 통해 score network가 잘 학습되었다면 모든 데이터 공간 상에서의 score를 계산할 수 있는 것이다.
이전 시점의 data에 score값을 더해 다음 시점의 data를 추정. 이때 local maximum 등을 벗어나기 위해 random noise를 더해준다.
임의의 데이터(random noise)에서 시작을 해서 score를 타고 올라가다 보면, 높은 확률값(샘플링 데이터와 유사한)의 데이터를 생성하는 것이 가능해진다.
다음 x˜값을 update하는 과정을 반복함으로써 true data distribution을 따르는 샘플링이 가능해지는 것이다.
즉, p_data(x)에서 sample을 얻으려면 먼저 sθ(x) ≈ ∇x log pdata(x) 가 되도록 score network를 훈련한 다음 이 score function sθ(x)을 사용해 Langevin dynamics로 샘플을 대략적으로 얻는 것이다. = score-based generative modeling의 framework의 핵심 아이디어
Chanllenges of score-based generative modeling
하지만 나이브한 score-based generative model은 몇 가지의 문제점이 존재하는데, 논문에서는 Manifold Hypothesis, inaccurate low data density data, slow mixing of Langevin dynamic 총 3가지를 지적하고 있다.
1. The manifold hypothesis
: 실제 데이터 분포는 low dimensional manifold에 집중되는 경향이 있다고 주장하는 가설
manifold : dataset을 잘 표현하는 subspace
이 가설에 의하면 SBGM은 아래 두 가지의 문제점을 갖게 된다.
1. 데이터 x가 low dimensional manifold에 국한될 때 데이터의 score를 정의할 수 없다
score는 ∇x log pdata(x) 이므로 gradient를 구할 수 없으니 정의가 불가능함
2. 데이터의 분포가 whole space일 경우에만 일관된 score estimate를 얻을 수 있다
본 논문에서는 Gaussian noise를 더함으로써 perturbated data distribution의 support를 whole space로 확장시켜 score matching이 일관되게 진행될 수 있도록 하였다.
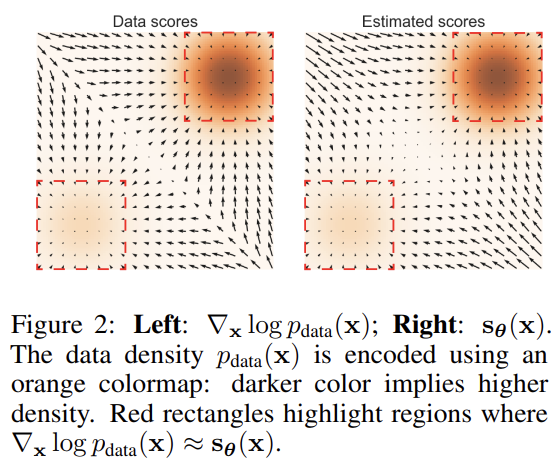
Figure 1 (좌)은 ResNet을 CIFAR-10에서 sliced score matching을 통한 score 추정을 진행했을 때의 결과로, noise를주지 않고 score function을 학습할 때 manifold hypothesis 하에서 어려움을 겪는 것을 확인할 수 있다.
(우) 에서는 약간의 Gaussian noise를 perturb줄 때 loss curve가 수렴하는 것을 보인다. 이는 Gaussian noise를 넣어줌으로 low demensional manifold에서 벗어나 perturbed data distributino이 온전히 R^D로 support 되기 때문이다.
2. Inaccurate score estimation with score matching
: 자연 상태에서 가져온 데이터 분포가 우리가 알고자 하는 분포와 유사하다면, 실제 분포의 low density 영역의 data는 많이 없을 것이다.
즉, 데이터 분포가 sparse하기 때문에 특히 low density region에서 데이터의 희소성으로 score matching이 정확하게 이루어지지 않는 현상을 의미한다. (score function의 정확도가 낮아질 수 있다.)
사진에서 데이터 분포에 대한 실제 score와 예측된 score(noise가 주어지지 않은 상태에서 학습한 모델이 예측한 score)가 다르게 나타남을 확인할 수 있다.
데이터가 주어진 부분(빨간색 점선) 내부의 예측은 정확하지만, 그 외 부분에 있어 오차가 발생한다.
(좌)에 비해 (우)의 중앙을 보면, 데이터가 적은 부분의 score가 제대로 구해지지 않는 것을 볼 수 있다.
이는 실제로 score function이 수렴하는지에 대한 이슈이며, sampling이 정상적으로 이루어지고 있는가에 대한 의문을 갖게 만든다.
3. Slow mixing of Langevin dynamics
low density의 score는 또 다른 문제가 있는데, 만약 data distribution이 low density regions로 나뉘게 된다면 Langevin dynamics가 제대로 작동하지 않을 수 있다는 것이다.
예로 아래와 같은 mixture distribution이 있다고 가정해보자.
π : data의 sampling을 결정하는 베르누이 분포
p1(x)와 p2(x)는 각각 정규화된 분포이며, 서로 다른 support를 가짐
(a) : 실제의 iid sampling 결과
(b) : Langevin dynamics를 사용할 때의 결과
이는 score function의 방식 때문에 나타나는 차이로, 설명하면 다음과 같다.
p1(x)의 support에서 p_data(x)는 아래와 같이 근사된다.
이 경우, score function은 다음과 같이 계산된다.
따라서 p1(x)의 support에서 score function은
에 의존한다.
마찬가지로, p2(x)의 support에서 score function은
에 의존한다.
위의 두 경우 모두에서 스코어 함수 ∇x log p_data(x)는 π에 의존하지 않는다. 이는 이론적으로 π 값이 샘플링에 영향을 미치지 않는다는 것을 의미한다. 즉, 실제 분포와 상관없이 균일하게 sampling이 된다는 것이다.
⇒ Langevin dynamics는 결국 원본(a)과 정확하지 않은 것(b)을 생성하게 되는 것이다.
원래 데이터의 score인 ∇x log pdata(x)는 π에 의존하지 않기 때문에 MCMC sampling의 진행 과정에서 low density를 반영하지 못한다고 할 수 있다. 이론적으로는 수렴하게 하기 위해선 Langevin dynamics는 작은 step size와 많은 수의 step을 사용해야 한다고 한다.
Noise Conditional Score Networks(NCSN): learning and inference
위 세 가지의 문제점을 극복하기 위해 논문에서는 perturbated data의 distribution을 이용하는 것이 score-based generative model에 적합하다고 결론을 내렸다.
perturb시킬 때 위 논문에서는 gaussian noise를 사용함
그 이유로는 아래와 같다.
1. Gaussian distribution은 whole space에서 정의되기 때문에, low demension manifold에 국한되지 않으며, 이는 manifold가설에 위배되지 않는다.
가우시안 분포는 전체 공간에서 확률 밀도를 가지며 모든 방향으로 확산되어 있음. 이는 가우시안 분포가 저차원 구조에 국한되지 않음을 의미함.
2. Large noise가 unperturbated data distribution에서 low density region을 채우는 효과가 있어 더 향상된 score estimation이 가능하다.
3. multiple noise level을 사용하여 실제 데이터 분포로 수렴할 수 있는 noise-perturbed distribution의 sequence를 얻을 수 있다.
또한, simulated annealing과 annealed importance sampling의 정신으로 intermediate distribution을 활용해서 Langevin dynamics를 향상시킬 수 있다고 한다.
이러한 관점에서 논문의 저자는 아래의 두 가지 시도를 하였다.
1. 다양한 레벨의 noise를 사용해 perturbated data를 만든다.
2. single conditional score network로 모든 noise level에 대해 학습을 진행했다.
이 두 목적을 이루기 위해 다음과 같은 score network, the training objective, annealing schedule for Langevin dynamic을 설명한다.
Noise Conditional Score Networks
1. sigma scheduling
noise의 variance가 점점 커지는 형태로 이를 정의해서 이전 단계의 σ와 이후 단계의 σ비를 같게 설정하는 기하적 순열(=등비수열)(geometric sequence)를 이용했다.
시간에 따라 변화하지 않는 고정된 크기의 sigma(σ)를 사용하면 trade off 관계가 발생한다.
noise(= σ)가 크면 low density region에서의 score가 잘 정의되지만, 실제 data distribution을 너무 많이 perturb해 정확도가 낮아진다는 단점을 가진다.
반대로 noise가 작으면 original data distribution에 비교적 작은 corruption을 할 수 있지만 sparse region에서의 score가 잘 정의되지 않아 오차가 발생하는 것이다.
이러한 두 상황의 장점을 모두 취하기 위해 σ를 scheduling해서 변화시키며 넣어줘서 모든 noise level에 관해 학습을 진행하는 것이다. 기존의 Langevin dynamics로는 low density 부분을 accurate 할 수 없기에, data의 density의 σ(분산)를 키워서 low data density 부분에도 data가 존재하게끔 하는 것이다.
low data density가 있을 때의 score function의 경우
σ 를 키웠을 때의 score function의 경우
그러나 σ 가 너무 크면 data의 정확한 density를 추정할 수 없으므로, σ 를 계속해서 바꿔주는 것이다.
이 σ를 계속해서 바꿔주는 이 방법을 annealed Langevin dynamics라고 하는 것이고, score function에 σ 를 조건부로 넣어주는 모델을 NCSN이라고 정의한다.
아래 그림에서 보이듯, σ가 작으면 low density를 잘 맞추지만, score function이 존재하지 않는 부분이 생기고, σ가 클 수록 모든 부분에 대해서 score function이 구해지는 것을 볼 수 있다. 이를 통해 NCSN 모델은 σ_large를 σ_small로 바꾸면서 sampling 결과를더 좋게 만드는 것이다.
multiple scales of noise perturbations
하지만 이렇게 noise의 scale이 단계마다 다르면 각 단계마다의 obejective의 크기가 달라질 수 있다. 그렇기에 각 단계마다 적절한 weight를 가해서 objective를 더해줄 필요가 있다.
즉, NCSN은 기존의 sθ(x)에 대해서 조건부로 noise를 주는 것인데, 여기서의 noise를 σ로 정의하여 score function을 새롭게 정의한다.
근데 이 변한은 그냥 할 수 없는 것. y = g(x)라 하고, 단순히 x 자리에 g-1(y)를 넣는 것으로 끝나지 않는다.
함수를 정의하던 X의 영역에서 Y의 영역으로 변화가 일어난 것으로, X의 support를 A라고 했다면, Y의 support를 단순히 A라고 말 할 수 없다. (정의역(support)에 대해 Y를 적분하면 X에 대한 적분과 달리 결과값이 1이 나오지 않을 수 있다.)
Ex:
이는 변수를 변환한다고 해서 전체 적분값이 1이 된다는 것은 전혀 변하지 않았으나, 어떤 확률변수에 존재하는 '특정한 점'은 속도가 달라지게 움직였기 때문이라고 볼 수 있다.
그래서 Jacobian을 사용하는 것!
정리하면,
변환을 함에 있어서 support를 다시 정의해야 하고, 변수가 연속적인 경우 그 변화의 속도를 반영하기 위한 Jacobian을 사용하게 되는 것이다.
이산(discrete) 변수에 대해서 Jacobian을 정의하지 않는 이유 : 연속적인 변수에 대해서는 변화하는 속도 개념이 존재하지만, 이산적인 변수에서는 이 개념이 존재하지 못한다. 왜냐하면 미분의 정의와 어긋나기 때문이다. 즉, 변화의 속도를 체크하기 위한 아주 작은 ε을 정의할 수 없다.